Es gibt nichts wichtigeres als Backup Backup und hab ich schon gesagt: Backup? Gerade in Zeiten von Emotet und Co muss man extrem aufpassen. Ich möchte in diesem Beitrag meine Backupstrategie vorstellen.
Auf die Idee gebracht hat mich https://flxn.de/posts/nextcloud-backup-to-freenas/ . Ich habe die Idee nur etwas abgewandelt.

Die Situation
Ich habe viele Server, darunter einige Nextclouds, Webserver und Mailserver. Auf den Servern ist notorisch wenig Platz, aber dafür ist auf dem TrueNAS genug Platz! Das TrueNAS ist nicht öffentlich im Netz, die Server allerdings schon, was diese natürlich zum idealen Angriffsziel machen. Alle Server basieren auf Linux bzw. BSD.
Die Backupstrategie
Ich habe meine Backupstrategie in mehrere Stufen eingeteilt.
Grundsätzliches
Pull nicht Push: Holt euch die Backups immer so, dass der Backupserver (der nur lokalen Zugriff zulässt) vom entfernten System abholt. Sollte der Server einmal übernommen werden, kann sonst der Angreifer auch den Backupserver übernehmen, bzw. weiß sofort von den Offsite-Backups.
Teste dein Backup: Teste auch ob das wiederherstellen deines Backups funktioniert. Am besten regelmäßig! Ein nicht getestetes Backup ist quasi kein Backup.
Stufe 1: Versionierung
Die erste Stufe schützt vor versehentlichem Löschen einer Datei. Speichert man die Änderungshistorie bzw. verschiedene Versionen können diese wiederhergestellt werden. Am einfachsten geht das bei ZFS (Dateisystem) mit regelmäßigen Snapshots bzw. bei der Nextcloud mit dem Addon „Versions“. Das geht natürlich nicht bei allen Servern z.B. dem Mailserver, aber hilft bei einfachen Fehlern enorm.
Stufe 2: Einfache Onsite Snapshots
Viele meiner Maschinen sind als VM abgebildet. Jeder Virtualisierungshost bietet die Funktion der Snapshots bzw. des Backups. Dabei wir dein Snapshot der gesamten VM angelegt. Dies hilft bei Fehlkonfigurationen oder dem versehentlichen Löschen größerer Dateien. Es kann auch helfen, wenn man sich einen Verschlüsselungstrojaner eingefangen hat, aber in der Regel wartet dieser sehr lange, um auch ältere Snapshots zu erwischen. Hier speichere ich meist 7 Tage.
Stufe 3: Offsite-Backup
Das Offsite-Backup möchte ich in diesem Beitrag näher erklären. Ich hole mir dabei aktiv die Daten der Server ab und speichere diese auf einem TrueNAS. Wie ich das genau umgesetzt habe ist weiter unten beschrieben.
Der Backupserver sollte sich natürlich auch in einem anderen Rechenzentrum, bzw. an einem anderen Standort befinden.
Stufe 3,5: Ein weiteres Offsite-Backup mit einer anderen Methoden
Das Offsite-Backup sollte auch mit einer anderen Methode auf den gleichen oder einen anderen Server kopiert werden. So kann man systematische Fehler im Backupsystem vermeiden. Holt man sich z.B. mit dem ersten Offsite-Backup die Snapshots der VM ab, sollte man mit einem zweiten Backup stupide die Daten mit rsync abholen. Dies hilft, sollte z.B. der Snapshot nicht reparabel defekt sein oder sollte die Backupmethode die Backups zerstört haben.
Stufe 4: Offline-Backup vom Backup
Im schlimmsten Szenario muss man davon ausgehen, dass auch der Backupserver von einem Angreifer übernommen worden ist. Ich hole mir dazu einmal die Woche die Backups auf eine externe Festplatte und ziehe diese danach vom Server wieder ab. Das hilft natürlich nicht, wenn der Angreifer längere Zeit auf dem Backupserver ist, aber zumindest eine weitere Hürde.
Traumhaft wäre natürlich ein offline-Backup mit mehreren Festplatten, die sich idealerweise dann auch noch nicht am gleichen Standort oder in einem Brandschutztresor befinden :).
Die Umsetzung der Stufe 3: Offsite-Backup mit TrueNAS
Stufe 1 und 2 müssen je nach System selbst umgesetzt werden. Stufe 3 kann relativ einfach mit TrueNAS eingerichtet werden. Auf die Idee hat mich wie bereits erwähnt Felix gebracht (vgl. https://flxn.de/posts/nextcloud-backup-to-freenas/ ) gebracht. In seinem Blog erklärt Felix bereits wie ein Backup mit TrueNAS bzw. FreeNAS umgesetzt werden kann. Ich habe die Idee lediglich insoweit modifiziert, dass die verschiedenen Versionen der Backups nicht auf dem Server selbst, sondern auf dem Backupserver erstellt bzw. gespeichert werden.
Im Folgenden bezeichne ich den TrueNAS-Server als „Backupserver“ und als Beispiel für das System, welche gebackupt werden soll „Webserver“.
Schritt 1: SSH-Verbindung mit Webserver aufbauen
Als Übertragungsweg wollen wir rsync über SSH verwenden. Dazu muss zunächst ein SSH-Schlüssel-Paar erstellt und auf den Servern verteilt werden. Nutzt am besten für jeden Server ein individuelles Schlüsselpaar. Wie das geht, ist im Internet 100x dokumentiert. Ein Beispiel: https://www.thomas-krenn.com/de/wiki/OpenSSH_Public_Key_Authentifizierung_unter_Ubuntu
Achtung: Bevor ihr weiter macht, solltet ihr euch per Konsole im TrueNAS mindesten einmal erfolgreich mit dem Webserver verbunden haben. Hinweis: Passwort-Geschützte SSH-Keys werden bei automatischen Backups nicht unterstützt.
Schritt 2: rsync-Backup-Jobs einrichten
Hier können wir auf die komfortable Funktion von TrueNAS zurückgreifen. In der UI (TrueNAS) unter Tasks -> Rsync Tasks -> Add kann man einfach neue Jobs hinzufügen:
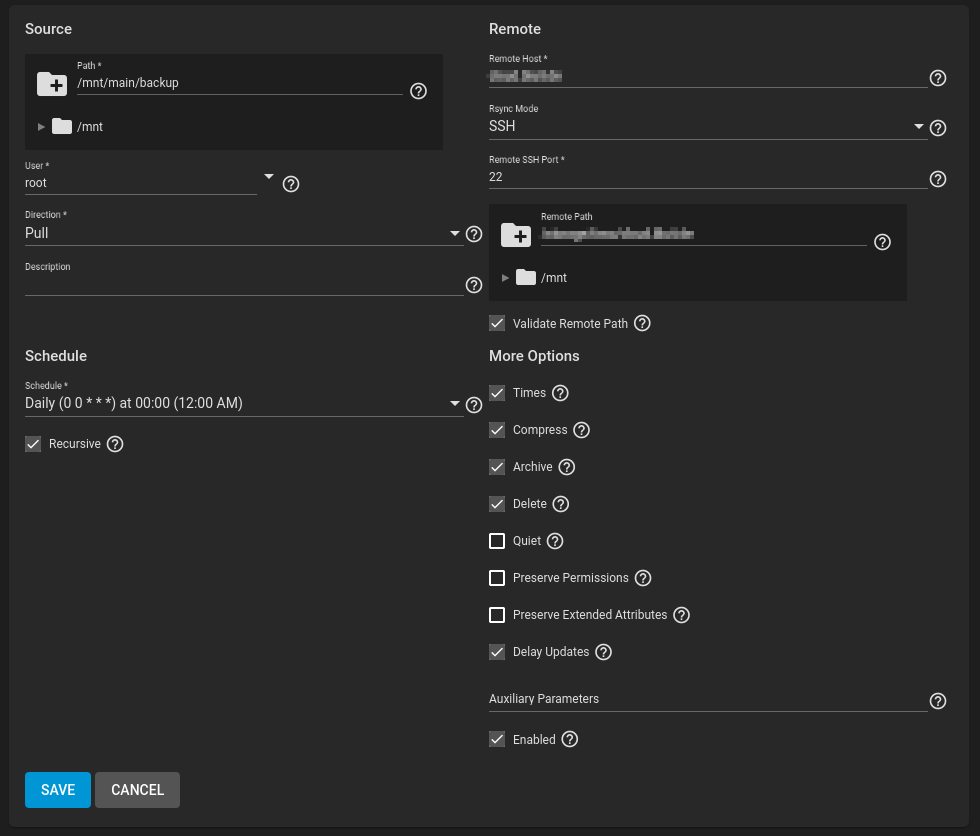
Die Wichtigsten Einstellungen dabei:
- Source Path: Der Ordner auf dem Backupserver auf dem das Backup abgespeichert werden soll. Es ist sehr hilfreich, für die Backups ein eigenes ZFS-Dataset anzulegen. Warum zeigt sich später!
- User: Der Benutzer auf dem Backupserver und Remote-Server (für SSH)
- Schedule: Wie oft soll das Backup durchgeführt werden?
- Remote Host: Der FQDN für den SSH-Zugriff auf den Webserver. Hier kann auch mit user@remotehost.de ein Benutzer angegeben werden.
- Remote Path: Der Ordner auf dem Webserver, der gespeichert werden soll
- Archive: aktivieren! Das ist wichtig um Berechtigungen und Benutzer zu erhalten
- Delete: aktivieren! Das ist wichtig, damit auch gelöschte Daten synchronisiert werden
Den Rest kann man im default belassen. Es können nun viele verschiedene Backup-Jobs z.b. für verschiedene Verzeichnisse oder verschiedene Server angelegt werden. Wenn ihr in der Übersicht der rsync-Jobs einen einzelnen Job anklickt und „Run now“ klickt, kann der Job getestet werden. Je nach größe des Backups kann das natürlich etwas dauern.
Das tolle an rsync: Das erste Backup dauert lange, danach wird nur noch der DIFF gesichert und das Backup sollte deutlich schneller gehen!
Schritt 3: Snapshots der Backups
Nun kommt der Punkt an dem ich mich von Felix (vgl. https://flxn.de/posts/nextcloud-backup-to-freenas/ ) unterscheide: Nach einem erfolgreichen rsync-Job lege ich nun ein Snapshot des Backups an. Warum? So kann ich auf verschiedene Versionen des Backups zurück greifen und kann sogar fein-granular einzelne Dateien wiederherstellen. Das ist vor allem sinnvoll, wenn man identifizieren kann, ab wann ein System potentiell kompromittiert ist. Bzw. wenn man weiß, ab wann eine Datei fehlt oder defekt war.
Unter Tasks -> Periodic Snapshot Tasks kann in TrueNAS bequem ein regelmäßiger Snapshot eingerichtet werden. Ich habe täglich gewählt und speichere ein Jahr. Achtet darauf, dass der Snapshot-Zeitpunkt nicht zeitgleich zum Backup-Zeitpunkt stattfindet.
Jetzt zeigt sich auch, warum es hilfreich ist, für die Backups ein eigenes Dataset anzulegen: Die Snapshots können nämlich auf verschiedene Datasets angewendet werden. So könnt ihr verschiedene Zeitpunkte oder Speicherfristen für verschiedene Backups festlegen.
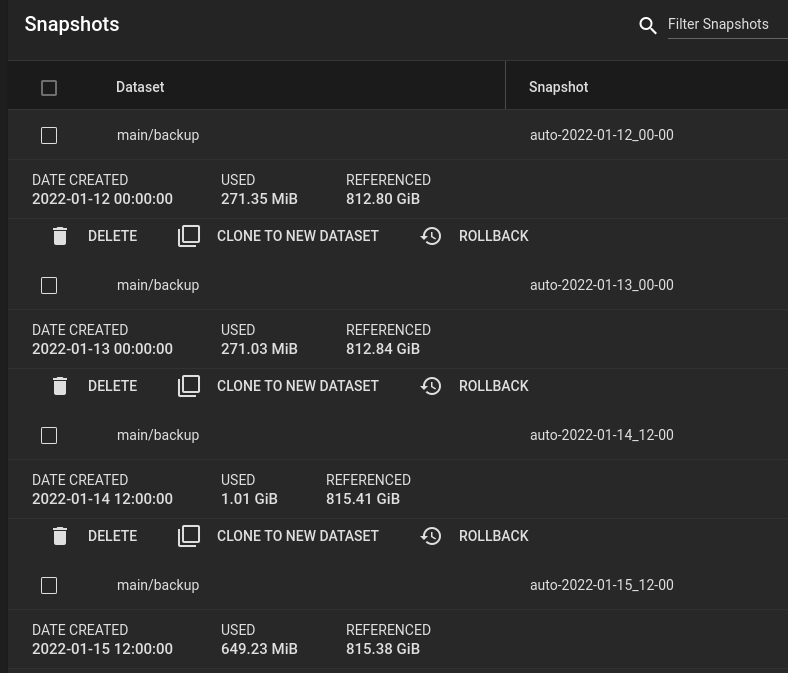
Sieht man sich nun die einzelnen Snapshots an, ist zu erkennen, dass ZFS sehr effizient ist und lediglich den DIFF speichert. So verbrauchen Snapshots nur sehr geringen Speicherplatz. Zum Wiederherstellen einzelner Versionen einfach auf „Clone to new Dataset“ klicken. Es wird dann ein neues Dataset angelegt auf dem die Daten durchsucht werden können.