Herzlich Willkommen auf meinem kleinen privaten Blog!
Dieser Blog ist vor langer Zeit entstanden um die daheim gebliebenen mit Fotos und Geschichten über meinen Neuseelandaufenthalt zu informieren. Mittlerweile sind aber auch andere Geschichten dazu gekommen. Neben einigen Hilfestellungen für Computerprobleme (vor allem Linux) berichte ich auch von meinem Onlineshop shop.blinkyparts.com. Schaut euch einfach ein bisschen auf meiner Seite um und hinterlasst einen Kommentar.
Mit dem Release von Ubuntu 24.04 LTS hat es Fangfrisch endlich in die offiziellen Paketquellen geschafft. In diesem Beitrag zeige ich euch, wie ihr Fangfrisch installiert, konfiguriert und mit freien ClamAV-Datenbanken ergänzt – inklusive Beispieldatei zum sofortigen Einsatz.
Was ist Fangfrisch?
Fangfrisch ist ein Sicherheitswerkzeug, das als Ergänzung zu ClamAV dient. Im Gegensatz zum offiziellen ClamAV-Tool freshclam, erlaubt Fangfrisch das Herunterladen und Aktualisieren von zusätzlichen, inoffiziellen Virendefinitionsdatenbanken. Dazu zählen Quellen wie SaneSecurity, URLHaus oder TwinWave. Der Fokus liegt auf besserem Schutz vor 0-Day-Malware, Phishing-Links, bösartigen Makros und vielem mehr.
Ein großer Pluspunkt: Fangfrisch wurde von Anfang an sicherheitsbewusst entwickelt und ist darauf ausgelegt, von einem unprivilegierten Benutzer ausgeführt zu werden.
Warum Fangfrisch?
Mit Ubuntu 24.04 LTS ist Fangfrisch per APT direkt installierbar:
sudo apt install fangfrisch
Das ist erfreulich – weniger erfreulich ist allerdings die teilweise veraltete Dokumentation. Deshalb dieser Blogbeitrag, um die aktuelle Konfiguration zusammenzufassen.
Konfigurationsdatei anpassen
Nach der Installation öffnet ihr die Konfigurationsdatei:
sudo vim /etc/fangfrisch.confsudo vim /etc/fangfrisch.conf
Dort können einzelne Datenquellen aktiviert und angepasst werden. Ich konzentriere mich hier auf die frei verfügbaren Datenbanken.
Übersicht empfohlener freier Signatur-Datenbanken
🛡️ SaneSecurity
Bereits vollständig in Fangfrisch integriert
Enthält Signaturen für 0-Day-Malware, Phishing-URLs, Spam-Mails, Double-Extension-Exes etc.
Bezieht auch Quellen wie Phishtank.com
[sanesecurity] enabled = yes
🔗 URLHaus (abuse.ch)
Sammlung von bösartigen URLs
Sehr effektiv gegen Malware-Links in E-Mails
[urlhaus] enabled = yes max_size = 5MB
🇫🇷 SecuriteInfo
Französischer Anbieter mit sehr umfangreichen Signaturen
Kostenlose Version: nur ältere Signaturen (älter als 30 Tage)
Für aktuelle Signaturen → kostenpflichtig
Registrierung notwendig
ID: Account anlegen, dann einloggen unter „Installation“ dann in den Download-URLs die customer_id extrahieren: /get/signatures/[customer-id]/*.hdb
[securiteinfo] enabled = yes customer_id = abcdef123456 # Eigene ID eintragen
Ab sofort lädt Fangfrisch regelmäßig alle konfigurierten Signaturen herunter und speichert sie unter /var/lib/clamav.
Integration in Mailfilter (SpamAssassin, rspamd)
Fangfrisch ist kein Virenscanner, sondern nur ein Feed-Manager. Vergesst daher nicht, ClamAV korrekt in eure Mailfilter (z.B. SpamAssassin oder rspamd) einzubinden – dazu gibt’s im Netz genügend Anleitungen.
Fazit
Mit Fangfrisch holt ihr das Maximum aus ClamAV heraus – gerade im Mailserver-Umfeld ist die Erkennung von 0-Day-Phishing und Makroviren deutlich besser als mit den offiziellen Signaturen allein.
Viel Spaß beim Absichern eurer Server – und bleibt sauber! 🛡️🐧
Du möchtest deine virtuelle Maschine von der Hetzner Cloud auf deinen eigenen Proxmox Server migrieren? Diese ausführliche Anleitung zeigt dir, wie du eine 1:1 Migration durchführst – ohne Datenverlust und mit minimaler Downtime.
Warum von Hetzner Cloud zu Proxmox wechseln?
Die Migration von Hetzner Cloud zu einem eigenen Proxmox Server bietet mehrere Vorteile:
Kosteneinsparung: Langfristig günstiger als Cloud-Hosting
Vollständige Kontrolle: Eigene Hardware und Konfiguration
Bessere Performance: Dedizierte Ressourcen ohne Sharing
Datenschutz: Deine Daten bleiben auf eigener Hardware
Voraussetzungen für die Migration
Bevor du beginnst, stelle sicher, dass du folgende Komponenten bereit hast:
Funktionierenden Proxmox Server
Hetzner Storage Box oder ausreichend Speicherplatz
SSH-Zugang zu beiden Systemen
Backup deiner wichtigen Daten (Sicherheit geht vor!)
Schritt 1: Hetzner Cloud Instanz vorbereiten
Zuerst musst du deine VM ordnungsgemäß herunterfahren, um Dateninkonsistenzen zu vermeiden.
# VM sauber herunterfahren (vor dem Rescue-Modus)
sudo shutdown -h now
Wichtig: Starte anschließend das Rescue-System über die Hetzner Cloud Console. Dies gibt dir vollständigen Zugriff auf die VM-Hardware.
Schritt 2: Festplatte im Hetzner Rescue System klonen
Storage Box mounten
# Verzeichnis für Storage Box erstellen
mkdir -p /mnt/storagebox
# Mount über SMB/CIFS (ersetze username und password)
mount -t cifs //username.your-storagebox.de/backup /mnt/storagebox -o username=username,password=yourpassword
# SSH-Schlüssel-basierte Verbindung (Alternative)
# mkdir -p ~/.ssh
# echo "your-storage-box-ssh-key" >> ~/.ssh/authorized_keys
# sshfs username@username.your-storagebox.de:/ /mnt/storagebox
Festplatte identifizieren und sichern
# Verfügbare Festplatten anzeigen
lsblk
fdisk -l
# Festplatte klonen mit Kompression (spart Zeit und Speicher)
# WICHTIG: /dev/sda durch die korrekte Festplatte ersetzen
dd if=/dev/sda bs=64M status=progress | gzip > /mnt/storagebox/hetzner-vm-backup.img.gz
Pro-Tipp: Die Kompression mit gzip reduziert die Dateigröße erheblich und beschleunigt die Übertragung.
Schritt 3: Image auf Proxmox Server übertragen
Storage Box auf Proxmox mounten
# Storage Box auf Proxmox Server mounten
mkdir -p /mnt/storagebox
mount -t cifs //username.your-storagebox.de/backup /mnt/storagebox -o username=username,password=yourpassword
# Komprimiertes Image entpacken und lokal speichern
gunzip -c /mnt/storagebox/hetzner-vm-backup.img.gz > /var/lib/vz/images/hetzner-vm-backup.img
Virtuelle Maschine in Proxmox erstellen
# VM mit passenden Spezifikationen erstellen
qm create 100 \
--name migrated-vm \
--memory 2048 \
--cores 2 \
--net0 virtio,bridge=vmbr0 \
--ostype l26 \
--cpu host \
--bios seabios
# Disk-Image importieren
qm importdisk 100 /var/lib/vz/images/hetzner-vm-backup.img local-lvm
# Importierte Festplatte zur VM hinzufügen
qm set 100 --scsi0 local-lvm:vm-100-disk-0
# Boot-Konfiguration setzen
qm set 100 --boot c --bootdisk scsi0
Wichtig: Passe RAM, CPU-Kerne und Netzwerk-Bridge entsprechend deiner ursprünglichen VM-Konfiguration an.
Schritt 4: Erste Konfiguration nach dem Boot
VM starten und Zugang herstellen
Starte nun die VM über die Proxmox Web-Konsole. Der erste Boot kann länger dauern, da das System die neue Hardware erkennt.
Hinweis: Standardmäßig ist eine englische Tastatur konfiguriert!
Deutsches Tastaturlayout aktivieren
# Sofortige Umstellung auf deutsches Layout
sudo loadkeys de
# Permanente Konfiguration
sudo dpkg-reconfigure keyboard-configuration
# Wähle: Generic 105-key PC → German → German
# Alternative: Über localectl
sudo localectl set-keymap de
Schritt 5: Cloud-Init deaktivieren
Cloud-Init kann in der Proxmox-Umgebung Probleme verursachen und sollte deaktiviert werden:
Das größte Problem nach der Migration ist meist die Netzwerk-Konfiguration. Hetzner Cloud und Proxmox verwenden unterschiedliche Interface-Namen und Konfigurationsmethoden.
Konkurrierende Netzwerk-Systeme identifizieren
# Aktive Netzwerk-Services prüfen
systemctl status networking
systemctl status systemd-networkd
systemctl status NetworkManager
Lösung: Netplan verwenden (empfohlen für Ubuntu 18.04+)
# VM stoppen
qm stop 100
# CPU-Typ auf 'host' setzen
qm set 100 --cpu host
# BIOS statt UEFI verwenden
qm set 100 --bios seabios
# IDE statt SCSI-Controller (bessere Kompatibilität)
qm set 100 --ide0 local-lvm:vm-100-disk-0
qm set 100 --boot order=ide0
# Serial Console für besseres Debugging
qm set 100 --serial0 socket
Problem: Netzwerk funktioniert nicht dauerhaft
Ursache: Mehrere Netzwerk-Management-Systeme konkurrieren
Lösung:
Cloud-Init komplett deaktivieren
Nur ein Netzwerk-System verwenden (Netplan ODER interfaces)
Korrekte Interface-Namen verwenden
Problem: Interface-Name unbekannt
# Alle verfügbaren Interfaces anzeigen
ip link show
ls /sys/class/net/
# Typische Namen:
# - ens18 (moderne Ubuntu-Versionen)
# - eth0 (ältere Versionen)
# - enp0s18 (bestimmte Konfigurationen)
Fazit
Die Migration einer VM von Hetzner Cloud zu Proxmox ist durchaus machbar und bietet langfristig viele Vorteile. Die kritischen Schritte sind:
Saubere Vorbereitung: VM ordnungsgemäß herunterfahren
Vollständiges Backup: 1:1 Kopie der Festplatte erstellen
Korrekte Hardware-Konfiguration: CPU, RAM und Storage anpassen
Netzwerk-Bereinigung: Cloud-Init deaktivieren und Netplan konfigurieren
System-Optimierung: Updates und Sicherheits-Anpassungen
Mit dieser Anleitung solltest du deine VM erfolgreich migrieren können. Bei Problemen ist es wichtig, die Logs zu analysieren und systematisch vorzugehen.
Hast du Fragen zur Migration oder sind Probleme aufgetreten? Teile deine Erfahrungen in den Kommentaren!
Da ich selbst in einige Fehler gelaufen bin, möchte ich hier eine Kurzdoku geben: Es reicht leider nicht aus einen mysqldump von MariaDB zu nehmen und dann in mysql zu importieren. Das Führt zu Fehlern.
Offenbar hat mysql ein Problem mit folgendem Part:
CREATE TABLE `document` (
`id` binary(16) NOT NULL,
`document_type_id` binary(16) NOT NULL,
`referenced_document_id` binary(16) DEFAULT NULL,
`file_type` varchar(255) NOT NULL,
`order_id` binary(16) NOT NULL,
`order_version_id` binary(16) NOT NULL,
`config` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`sent` tinyint(1) NOT NULL DEFAULT 0,
`static` tinyint(1) NOT NULL DEFAULT 0,
`deep_link_code` varchar(32) NOT NULL,
`document_media_file_id` binary(16) DEFAULT NULL,
`custom_fields` longtext CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL,
`created_at` datetime(3) NOT NULL,
`updated_at` datetime(3) DEFAULT NULL,
`document_number` varchar(255) GENERATED ALWAYS AS (json_unquote(json_extract(`config`,'$.documentNumber'))) STORED,
Die Spalte „document_number“ wird mit json generiert. Das hat zu Fehlern geführt.
Der mit der Shopware-CLI erstellte mysql-dump war weitestgehend kompatibel. Ich musste lediglich ein Datumsfeld ändern, welches auf 0000-00-00 00:00:00 stand. Bisher sind keine Fehler aufgefallen. Ich hoffe das bleibt auch so!
Lustigerweise hat sich der create table Befehl von oben im neuen dump nicht geändert, wird aber jetzt von mysql akzeptiert. offenbar passiert vorher noch etwas magic was beim dump mit mysqldump nicht passiert.
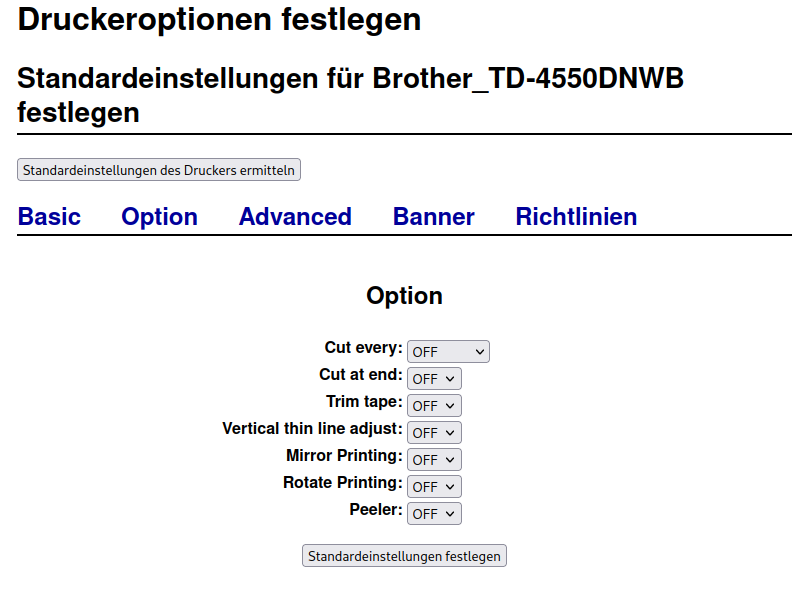
Ich hatte das Problem, dass ich den Brother TD-4550DNWB zwar zum laufen gebracht habe, aber die Druckqualität war Bescheiden.
Das Problem
Ich habe für Arch leider nicht den richtigen Treiber gefunden. Daher einen ähnlichen verwendet doch bei diesem wird der Druckkopf nicht heiß genug und kann die Farbe nicht sauber „ins Papier brennen“.
Die Druckqualität unter Linux (mit dem falschen Treiber)Die Druckqualität unter Windows (mit dem richtigen Treiber)
Für Arch habe ich nur das hier gefunden: https://aur.archlinux.org/packages/brother-td4100n
installieren. Natürlich kommen hier viele Fehlermeldungen aber ¯\_(ツ)_/¯.
Druck unter Linux mit der oben gezeigten Methode
Tipp: Ich musste „Select page size using document page size“ fest auswählen und die Document size exakt auf das einstellen, was im Display vom Drucker steht, ansonsten kam immer eine Leerseite mit.
Dank
Riesen Dank an @Jay16K@chaos.social für die mega gute Hilfe <3.
Update: Einstellunge
Ich wurde noch nach den Einstellungen gefragt:
Page Setup Paper size: 102mm x 152mm
Page Handling Page Scaling: Fit to Printable Area Auto Rotea and Center Select page size using document page size
Außerdem habe ich bemerkt, dass man den Drucker über lpd in CUPS hinzfügen MUSS:
lpd://BRW7CDB98D109AD/BINARY_P1
Au0ßerdem bei den Standardeinstellungen folgendes einstellen, sonst kommt immer wieder ein neues Blatt mit raus:
Ich war dieses Jahr zum ersten mal auf dem Fusion-Festival. Was für ein Festival! Tolles Konzept, tolle Leute, wunderbare Begegnungen!
Lötworkshop goes Fusion Festival
Das Konzept
Die Fusion ist ein nicht kommerzielles Festival mit ~70.000 Menschen auf einem ehemaligen Flugplatz. Ich war bisher immer nur auf „Standard-Festivals“ wie Rock im Park, Southside oder Summer Breeze. Bei diesen Festivals gibt es oft nur Campen, Bier, Essen, Konzerte. Die Fusion bietet so viel mehr: Die Kultur und die Künstler stehen hier im Vordergrund und es gibt so unglaublich viel zu entdecken. Von Theater, über Kino zu Lichtinstallationen, interaktive Hotels, kleine Verschläge in die man Klettern kann, Baumhäuser, Feuershow, Flammenwerfer am Wegesrand, Workshops … und natürlich die Musik. Das passt leider nicht alles in diesen Blog und eine bloße Beschreibung wird dem auch nicht gerecht.
Das Ziel der Fusion ist den Veranstaltern zufolge „Ferienkommunismus“. Fernab der Gesellschaft soll eine Parallelgesellschaft entstehen, die frei von Zwängen und Kontrollen sein soll. Die Veranstalter legen nach eigenen Angaben großen Wert auf gegenseitige Toleranz sowie eine umweltschonende und unkommerzielle Ausrichtung des Festivals. Es gibt keine Großsponsoren und keine Werbung auf dem Festivalgelände. Auf dem Festivalgelände werden ausschließlich vegetarische und vegane Speisen angeboten.
Natürlich kostet alles Geld und auch der Eintritt (220€) ist nicht ohne, aber man merkt an so vielen Ecken und Stellen, dass man auf dem Festival nicht abgezockt wird. Wie oft mussten wir bei Rock im Park durch die Security und wehe man hat auch nur ein Fitzelchen selbst mitgebrachtes Trinken dabei!1!1 Das geht doch nicht, da würden doch überall Glasscherben rumfliegen und blablabla… Die Fusion so: Ach du willst dir ne Kiste Augustiner mit rein nehmen? Kein Stress, hier hast du einen Container in dem du danach dein Leergut weggeben kannst. Ach ja das Leergut spenden wir übrigens für nen guten Zweck!
Die Wege sind oft lang, wie praktisch wäre da ein Fahrrad? Achso. Ja man kann natürlich auch mit dem Fahrrad über das Gelände radeln, oder Einrad, oder Escooter, oder mit dem Bollerwagen, oder ….
Für das Fusion-Festival gibt es traditionell immer mehr Nachfrage als Tickets im Angebot sind. Auf die 70.000 verfügbaren Tickets kommen >100.000 Interessierte. Daher kann man sich nicht einfach ein Ticket kaufen und wer zuerst kommt mahlt zuerst, sondern man bewirbt sich um ein Ticket und wird dann ausgelost. Dabei bewirbt man sich als ganze Gruppe und erhält entweder für alle oder für keinen Tickets. Es gibt aber wohl immer kurz vor dem Festival Tickets in der Ticket-Börse von Menschen die kurzfristig doch nicht kommen können.
Nachts über das Gelände und man kommt aus dem staunen nicht mehr raus!
Die Hangars
Auf dem Gelände stehen zwölf ehemalige Flugzeughangars, die mit Rasen bewachsen sind. Diese werden für verschiedene Veranstaltungszwecke genutzt. Es gibt einige Bühnen, Bars, ein Theater und ein Kino in den Hangars… Und ein Workshophangar und genau bei diesem haben wir unser großes Lötworkshopzelt aufgeschlagen. Die Hangars haben jeweils eine Crew und organisieren sich selbst. Sie buchen teilweise auch selbst Acts und bereiten Aktionen vor, haben ein eigenes Ticket-Kontingent und auch eigene Campingbereiche.
Ein Blick in den Lötworkshop
Wir selbst haben 7 Crew Tickets bekommen und waren insgesamt mit 18 Leuten vor Ort. An den 5 Tagen kam dadurch wieder schönes Congress-Feeling auf. Wir hatten 20 Lötstationen dabei. Viele Festivalbesucher kamen wegen der Nibble-Klammern, andere wollten etwas reparieren und das alles natürlich rund um die Uhr. An den meisten Tagen konnten wir dank der vielen Helfer den Kurs auch rund um die Uhr nbieten. Schöne Gespräche, viel über Nachhaltigkeit und Reparatur diskutiert und natürlich viel gelötet!
Fazit
Ich hatte anfangs Bedenken, was die Fusion-Besucher mit dem Lötworkshop anfangen können… Kann man Druffis (nicht alle sind drauf!) nen Lötkolben in die Hand drücken? Kommt überhaupt jemand zum Löten? Aber 1000 Nibble-Klammern und 350 Einhörner, Katzen und Schmetterlinge haben gezeigt: Die Fusion Besucher kommen nicht nur zum Feiern und Party machen, sondern auch zum Lernen und geduldig mit dem Lötkolben Löten. Alleine der Kerl, der oben ohne in die Area gekommen ist und nur mal schnell gucken wollte. 6 Stunden später ging er mit einer Nibble-Klammer mit 38 LEDs aus dem Zelt und war überglücklich. Es waren einige mehr dabei als auf den Chaos Events, die sich trotz Neugier das Löten erstmal nicht zugetraut haben. Die meisten haben sich aber ganz schnell überzeugen lassen und waren dann positiv überrascht und begeistert von ihrem Lötergebnis. Es hat einen riesigen Spaß gemacht!
Und jetzt mal Schluss mit dem blabla und her mit den Fotos!
Ich werde öfter gefragt, was ich denn für ein $tool empfehlen würde. Im Bereich Löten möchte ich hier kurz zusammenfassen, was meine Empfehlungen sind.
Ich werde hier NICHT GESPONSERD und habe auch keinerlei Affiliate-Links! Es handelt sich um meine persönliche Erfahrung. Your mileage may vary. Schreibt mir gerne eure Tipps und Empfehlungen!
Beim Löten immer für einen sauberen Arbeitsplatz sorgen
Lötstation
Bei Lötstationen unterscheide ich in drei Kategorien. All diese Lötkolben und Stationen habe ich selbst getestet bzw. im Einsatz:
PINECIL (Lötkolben ~50€)
Absolute Empfehlung für den tieferen Einstieg
Super Chic und platzsparend!
Opensource-Hardware
Lange Lieferzeit + Zoll aus China
Nicht vergessen: Silikonkabel, Stromversorgung und Spitzen extra kaufen!
Weller WE1010 (Lötstation, ~150€)
Schöne Station mit guter Qualität
Etwas höherer Preis
Dafür alles dabei was man für den Anfang braucht
Eher für den stationären Bedarf gedacht
Schön großer Lötkolben
ERSA i-CON pico (Lötstation, ~150€)
Schöne Station mit guter Qualtiät
Etwas höherer Preis
Dafür alles dabei was man für den Anfang braucht
Eher für den stationären Bedarf gedacht
Lötkolben liegt sehr gut in der Hand
DAYTOOLS LS-99KIT (Lötstaiton, ~25€)
Günstig und schnell verfügbar (Starterkit)
Plastikbomber
Hält aber erstaunlich gut durch
Zubehör schon seit Jahren durchgängig verfügbar
Grundsätzlich würde ich jedem Anfänger zu einem Pinecil raten, man muss sich etwas damit beschäftigen, aber wenn man das ganze Zubehör zusammen hat ist das ein echt nettes Teil. Für den Mittelschweren Einsatz würde ich dann Weller oder Ersa mit ihren Einsteigermodellen empfehlen. Daytools LS-99KIT würde ich nehmen wenn es schnell gehen soll.
Bleifreies Lötzinn/Lot
Ich würde selbst nicht mehr mit verbleitem Lot arbeiten wenn nicht unbedingt nötig.
Dritte Hand: Irgendwas, wo man mal was einklemmen kann ist manchmal schon praktisch. Ansonsten nicht unbedingt nötig und meist bei Sets dabei.
Pinzetten: Für Kleinteile extrem praktisch. Ich mag die Pinzetten von Knippex. Es gibt aber auch günstigere Sets bei Amazon.
Lötunterlage: Hier geht alles von Holzbrett bis Silikonunterlage oder ESD-Matte. Die Silikondinger ziehen Staub magisch an, ansonsten finde ich ESD-Matten am angenehmsten.
Es gibt nichts wichtigeres als Backup Backup und hab ich schon gesagt: Backup? Gerade in Zeiten von Emotet und Co muss man extrem aufpassen. Ich möchte in diesem Beitrag meine Backupstrategie vorstellen.
Server – CC-BY-SA 3.0: https://commons.wikimedia.org/wiki/File:Wikimedia_Foundation_Servers-8055_35.jpg
Die Situation
Ich habe viele Server, darunter einige Nextclouds, Webserver und Mailserver. Auf den Servern ist notorisch wenig Platz, aber dafür ist auf dem TrueNAS genug Platz! Das TrueNAS ist nicht öffentlich im Netz, die Server allerdings schon, was diese natürlich zum idealen Angriffsziel machen. Alle Server basieren auf Linux bzw. BSD.
Die Backupstrategie
Ich habe meine Backupstrategie in mehrere Stufen eingeteilt.
Grundsätzliches
Pull nicht Push: Holt euch die Backups immer so, dass der Backupserver (der nur lokalen Zugriff zulässt) vom entfernten System abholt. Sollte der Server einmal übernommen werden, kann sonst der Angreifer auch den Backupserver übernehmen, bzw. weiß sofort von den Offsite-Backups.
Teste dein Backup: Teste auch ob das wiederherstellen deines Backups funktioniert. Am besten regelmäßig! Ein nicht getestetes Backup ist quasi kein Backup.
Stufe 1: Versionierung
Die erste Stufe schützt vor versehentlichem Löschen einer Datei. Speichert man die Änderungshistorie bzw. verschiedene Versionen können diese wiederhergestellt werden. Am einfachsten geht das bei ZFS (Dateisystem) mit regelmäßigen Snapshots bzw. bei der Nextcloud mit dem Addon „Versions“. Das geht natürlich nicht bei allen Servern z.B. dem Mailserver, aber hilft bei einfachen Fehlern enorm.
Stufe 2: Einfache Onsite Snapshots
Viele meiner Maschinen sind als VM abgebildet. Jeder Virtualisierungshost bietet die Funktion der Snapshots bzw. des Backups. Dabei wir dein Snapshot der gesamten VM angelegt. Dies hilft bei Fehlkonfigurationen oder dem versehentlichen Löschen größerer Dateien. Es kann auch helfen, wenn man sich einen Verschlüsselungstrojaner eingefangen hat, aber in der Regel wartet dieser sehr lange, um auch ältere Snapshots zu erwischen. Hier speichere ich meist 7 Tage.
Stufe 3: Offsite-Backup
Das Offsite-Backup möchte ich in diesem Beitrag näher erklären. Ich hole mir dabei aktiv die Daten der Server ab und speichere diese auf einem TrueNAS. Wie ich das genau umgesetzt habe ist weiter unten beschrieben.
Der Backupserver sollte sich natürlich auch in einem anderen Rechenzentrum, bzw. an einem anderen Standort befinden.
Stufe 3,5: Ein weiteres Offsite-Backup mit einer anderen Methoden
Das Offsite-Backup sollte auch mit einer anderen Methode auf den gleichen oder einen anderen Server kopiert werden. So kann man systematische Fehler im Backupsystem vermeiden. Holt man sich z.B. mit dem ersten Offsite-Backup die Snapshots der VM ab, sollte man mit einem zweiten Backup stupide die Daten mit rsync abholen. Dies hilft, sollte z.B. der Snapshot nicht reparabel defekt sein oder sollte die Backupmethode die Backups zerstört haben.
Stufe 4: Offline-Backup vom Backup
Im schlimmsten Szenario muss man davon ausgehen, dass auch der Backupserver von einem Angreifer übernommen worden ist. Ich hole mir dazu einmal die Woche die Backups auf eine externe Festplatte und ziehe diese danach vom Server wieder ab. Das hilft natürlich nicht, wenn der Angreifer längere Zeit auf dem Backupserver ist, aber zumindest eine weitere Hürde.
Traumhaft wäre natürlich ein offline-Backup mit mehreren Festplatten, die sich idealerweise dann auch noch nicht am gleichen Standort oder in einem Brandschutztresor befinden :).
Die Umsetzung der Stufe 3: Offsite-Backup mit TrueNAS
Stufe 1 und 2 müssen je nach System selbst umgesetzt werden. Stufe 3 kann relativ einfach mit TrueNAS eingerichtet werden. Auf die Idee hat mich wie bereits erwähnt Felix gebracht (vgl. https://flxn.de/posts/nextcloud-backup-to-freenas/ ) gebracht. In seinem Blog erklärt Felix bereits wie ein Backup mit TrueNAS bzw. FreeNAS umgesetzt werden kann. Ich habe die Idee lediglich insoweit modifiziert, dass die verschiedenen Versionen der Backups nicht auf dem Server selbst, sondern auf dem Backupserver erstellt bzw. gespeichert werden.
Im Folgenden bezeichne ich den TrueNAS-Server als „Backupserver“ und als Beispiel für das System, welche gebackupt werden soll „Webserver“.
Schritt 1: SSH-Verbindung mit Webserver aufbauen
Als Übertragungsweg wollen wir rsync über SSH verwenden. Dazu muss zunächst ein SSH-Schlüssel-Paar erstellt und auf den Servern verteilt werden. Nutzt am besten für jeden Server ein individuelles Schlüsselpaar. Wie das geht, ist im Internet 100x dokumentiert. Ein Beispiel: https://www.thomas-krenn.com/de/wiki/OpenSSH_Public_Key_Authentifizierung_unter_Ubuntu
Achtung: Bevor ihr weiter macht, solltet ihr euch per Konsole im TrueNAS mindesten einmal erfolgreich mit dem Webserver verbunden haben. Hinweis: Passwort-Geschützte SSH-Keys werden bei automatischen Backups nicht unterstützt.
Schritt 2: rsync-Backup-Jobs einrichten
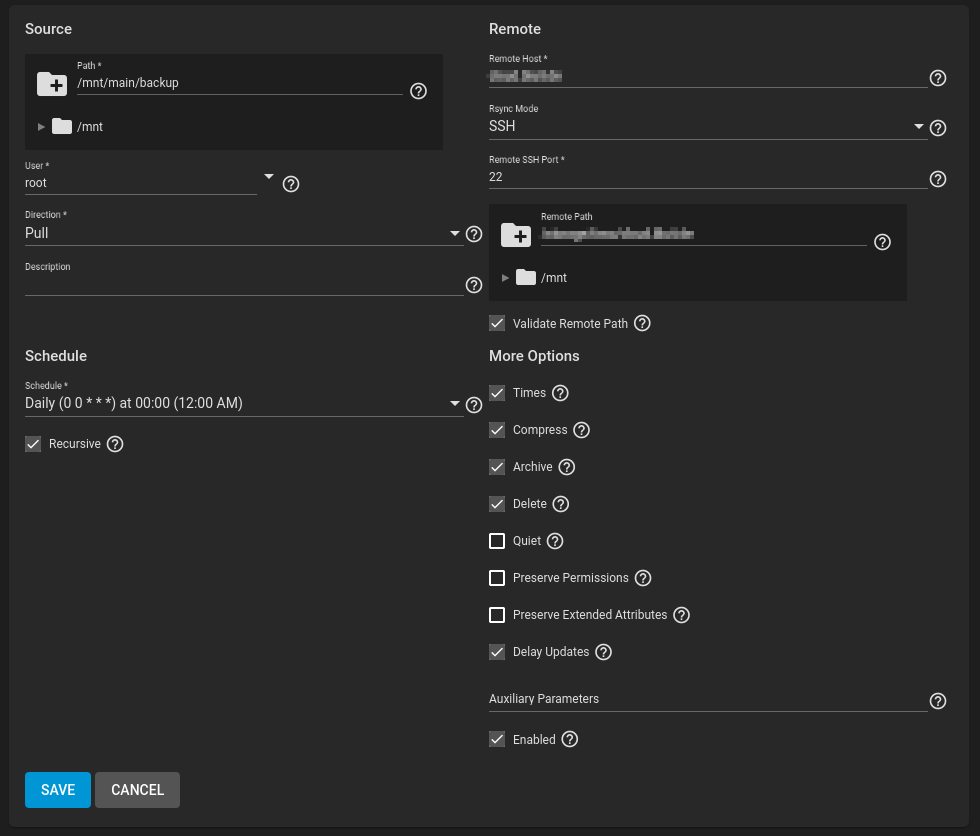
Hier können wir auf die komfortable Funktion von TrueNAS zurückgreifen. In der UI (TrueNAS) unter Tasks -> Rsync Tasks -> Add kann man einfach neue Jobs hinzufügen:
rsync-jobs mit TrueNAS
Die Wichtigsten Einstellungen dabei:
Source Path: Der Ordner auf dem Backupserver auf dem das Backup abgespeichert werden soll. Es ist sehr hilfreich, für die Backups ein eigenes ZFS-Dataset anzulegen. Warum zeigt sich später!
User: Der Benutzer auf dem Backupserver und Remote-Server (für SSH)
Schedule: Wie oft soll das Backup durchgeführt werden?
Remote Host: Der FQDN für den SSH-Zugriff auf den Webserver. Hier kann auch mit user@remotehost.de ein Benutzer angegeben werden.
Remote Path: Der Ordner auf dem Webserver, der gespeichert werden soll
Archive: aktivieren! Das ist wichtig um Berechtigungen und Benutzer zu erhalten
Delete: aktivieren! Das ist wichtig, damit auch gelöschte Daten synchronisiert werden
Den Rest kann man im default belassen. Es können nun viele verschiedene Backup-Jobs z.b. für verschiedene Verzeichnisse oder verschiedene Server angelegt werden. Wenn ihr in der Übersicht der rsync-Jobs einen einzelnen Job anklickt und „Run now“ klickt, kann der Job getestet werden. Je nach größe des Backups kann das natürlich etwas dauern.
Das tolle an rsync: Das erste Backup dauert lange, danach wird nur noch der DIFF gesichert und das Backup sollte deutlich schneller gehen!
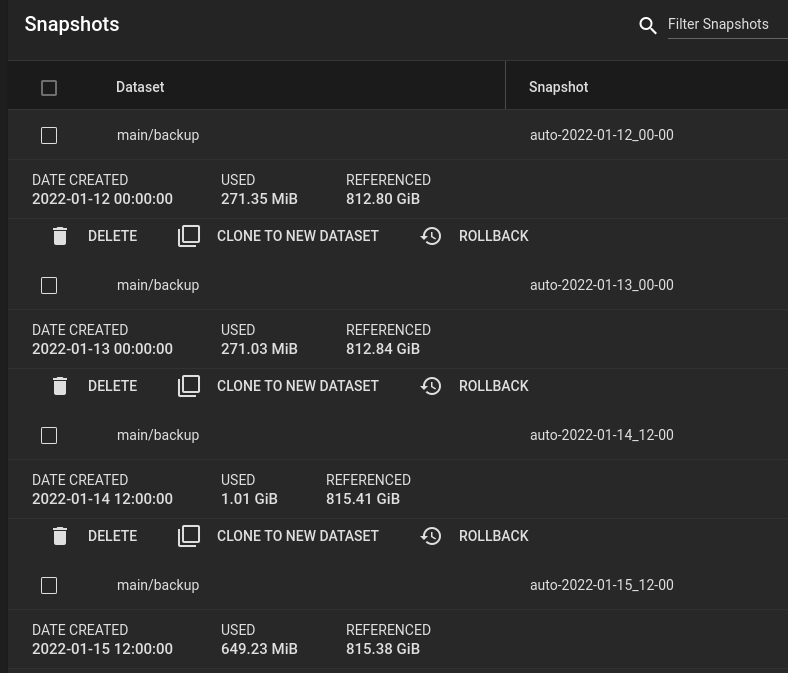
Schritt 3: Snapshots der Backups
Nun kommt der Punkt an dem ich mich von Felix (vgl. https://flxn.de/posts/nextcloud-backup-to-freenas/ ) unterscheide: Nach einem erfolgreichen rsync-Job lege ich nun ein Snapshot des Backups an. Warum? So kann ich auf verschiedene Versionen des Backups zurück greifen und kann sogar fein-granular einzelne Dateien wiederherstellen. Das ist vor allem sinnvoll, wenn man identifizieren kann, ab wann ein System potentiell kompromittiert ist. Bzw. wenn man weiß, ab wann eine Datei fehlt oder defekt war.
Unter Tasks -> Periodic Snapshot Tasks kann in TrueNAS bequem ein regelmäßiger Snapshot eingerichtet werden. Ich habe täglich gewählt und speichere ein Jahr. Achtet darauf, dass der Snapshot-Zeitpunkt nicht zeitgleich zum Backup-Zeitpunkt stattfindet.
Jetzt zeigt sich auch, warum es hilfreich ist, für die Backups ein eigenes Dataset anzulegen: Die Snapshots können nämlich auf verschiedene Datasets angewendet werden. So könnt ihr verschiedene Zeitpunkte oder Speicherfristen für verschiedene Backups festlegen.
Die Snapshots des Backup
Sieht man sich nun die einzelnen Snapshots an, ist zu erkennen, dass ZFS sehr effizient ist und lediglich den DIFF speichert. So verbrauchen Snapshots nur sehr geringen Speicherplatz. Zum Wiederherstellen einzelner Versionen einfach auf „Clone to new Dataset“ klicken. Es wird dann ein neues Dataset angelegt auf dem die Daten durchsucht werden können.
In der Binary Kitchen haben wir vor vier Jahren mit unseren Lötworkshops angefangen. Anfangs waren es nur 4 Zusammengeschnorrte Lötkolben, dann 20. Mittlerweile haben wir 40 Lötarbeitsplätze für unsere Lötworkshops und verleihen diese auch regelmäßig. Mittlerweile haben wir alles in schöne rote Kisten gepackt, warum und wie möchten wir hier mal etwas aufklären.
How it Started
Wenn wir Lötworkshops veranstalten sorgen wir für bis zu 40 Lötarbeitsplätze mit Unterlagen, Zangen, Licht, Strom, Lötkolben und und und und…. Insgesamt waren es ungefähr 10 große Eurokisten die irgendwann einfach nicht mehr handelbar waren. Dazu kam, dass wir viele kleinere Lötworshops haben wo nur 5-10 oder mal 20 Lötarbeitsplätze nötig waren und immer der gesamte Lötworkshop mitgezogen wurde.
Daher haben wir einen Paradigmenwechsel vollzogen hin zu einzelnen Arbeitsplätzen. Zunächst war die Idee von gelaserten Boxen die in Eurokisten passen, dann waren wir zufällig im Bauhaus und haben diese wunderschönen Metallboxen für 12,50€ gefunden! Zackfertig: Einzelner Lötarbeitsplatz-Koffer!
Haufenweise KistenModeschau mal anders, aber es zählen doch eh die inneren Werte!
How it’s Going
Wir haben die Koffer relativ einfach in vier Bereiche unterteilt, einfach um das Herumfliegen der Teile etwas einzuschränken und den Zusammenräumenden ein wenig Anleitung zu geben. Unser Lötworkshop besteht auch aus verschiedenen Lötkolben und Lötstationen, mit den vier Unterteilungen hat aber alles platz.
Der Koffer mit unseren alten LötstationenDer Koffer mit unseren neuen Lötstationen
Was ist alles drin?
Unser Lötarbeitsplatz besteht aus:
Lötstation + Lötkolbenhalter (Wir haben Ersa Pico gesponsort bekommen und haben noch die billigen von Pollin. Bald auch tolle Pinecils)
Knipex Seitenschneider (die großen, etwas unpraktischer, dafür unkaputtbar)
Lot (auf einer sehr kleinen Handrolle, stellt NIE ne 250g Rolle auf den Tisch! Kinder liebe es den Lötkolben da rein zu stechen /o\)
Entlötpumpe und Entlötlitze
Pinzette
Schraubenzieher (Schlitz)
Schutzbrille
Dritte Hand
Was braucht man sonst noch?
Das wichtigste sind wohl die Steckerleisten (man fährt sehr gut mit 3 Steckplätzen pro Arbeitsplatz) und gutem Licht.
Die aufgebauten Lötarbeitsplätze
Next Level Shit
Die Mintlabs Regensburg haben es aber auf die Spitze getrieben (I like!)! Zunächst auch mit einer selbst gelaserten Box gestartet, ging es über zu der echt robusten Metallbox. Bei den Mintlabs ist ALLES integriert und nur ein Stromanschluss geht rein. Superfancy!
Viele haben gefragt und hier gibts einen kleinen Quickie zu den tollen Gosund SP1 Zwischensteckdosen.
Die Gosund SP1 Schaltsteckdose mit Hardwareschalter an der Oberseite
Die Zwischensteckdose / Das Messgerät
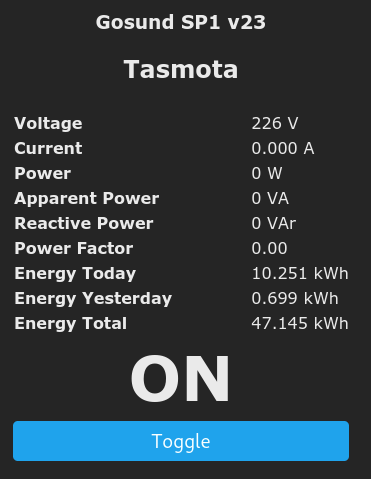
Die Gosund SP01 Schaltsteckdosen gibt es bei Aliexpress ab etwa 12€. Eigentlich ganz normale Schaltsteckdosen mit MQTT (für Heimautoamtisierung) und einem Hardwaretaster auf der Oberseite. Das Tolle: Die Dinger können auch Strom und allerlei anderer Dinge messen :).
Ein Screenshot der Gosund SP1 mit Tasmota Firmware
Im Bild sieht man, was man alles messen und per MQTT z.B. in eine Datenbank schieben kann \o/:
Spannung
Strom
Stromaufnahme
Scheinleistung
Blindleistung
Leistungsfaktor
Stromverbrauch heute/gestern und insgesamt
Das Flashen
Die original Firmware möchte man eigentlich nicht drauf haben und wenn ihr die Steckdose auspackt NICHT mit eurem Handy verbinden!
Die original Firmware hat einen kleinen Bug in der Version in der sie ausgeliefert wird. Dadurch ist es möglich die Steckdosen ohne aufschrauben und löten mit neuer toller Firmware zu flashen. Beschrieben ist das ganze hier:
Dazu gibt es nicht mehr zu sagen, die Seite beschreibt es wirklich sehr gut! Es lohnt sich gleich mehrere Schaltsteckdosen zu flashen :).
Das erfassen der Daten
Die Daten werden von der Steckdose erfasst und können dann z.B. in eine Influx Datebank geschrieben werden. Grafana (Darstellungssoftware) kann dann daraus tolle Werte und Graphen erstellen:
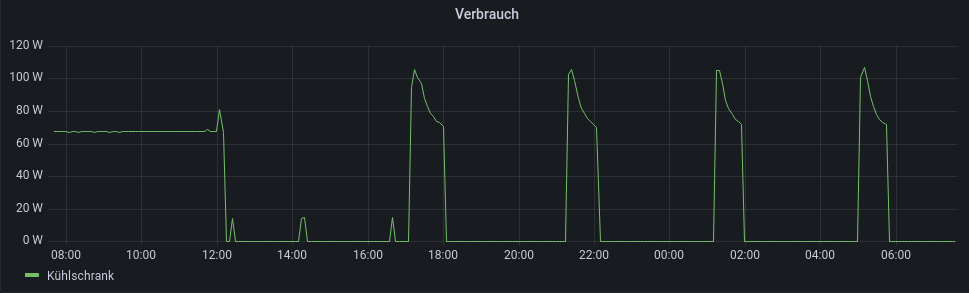
Der Stromverbrauch meines Kühlschranks vor und nach dem Abtauen
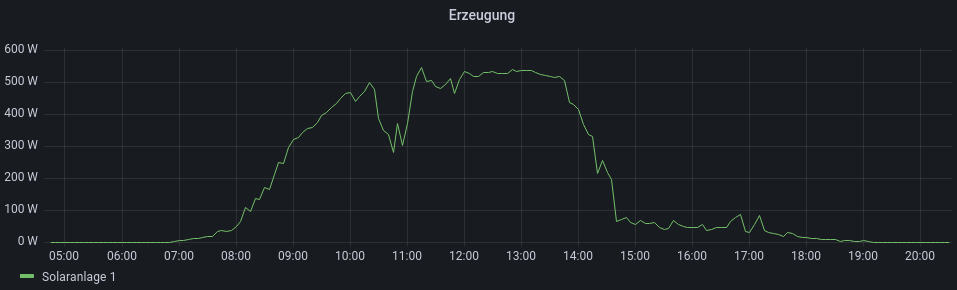
Das ganz geht übrigens auch anders herum, man kann damit auch die Stromerzeugung einer Solaranlage messen:
Geht direkt zum zweiten Teil (Server installieren und konfigurieren). Im ersten Teil flashe ich noch alte Zwischensteckdosen ;). Viel Spaß beim Strommessen 🙂
Mal wieder ein kleiner Quickie: Meine Freundin hat Probleme mit den Händen und hat bei einer Kollegin DIE ergonomische Tastatur ausprobiert: Microsoft Natural Ergnomic Keyboard 4000. Leider wird diese nicht mehr verkauft und die Nachfolgermodelle sollen wohl nicht so dufte sein.
Die gebrauchte Microsoft Natural Ergonomic Keyboard 4000 Tastatur
Naja gut, dann einfach ebay Kleinanzeigen gesucht, gefunden und enttäuscht worden: Tastatur ist leider defekt angekommen. Die Tastatur wurde einfach nur als unbekanntes USB-Gerät erkannt -.-. Zuerst hatten wir die Treiber in verdacht und wollten schon aufgeben, da hat uns ein Freund den Tipp gegeben: Schaut euch mal das Kabel an.
Tada! Da ist der Fehler. Eine Kabelquetschung, fast unsichtbar und kaum zu spüren
Der Übeltäter im Kabel
Naja gut. Kabel tauschen.. hmm.. oder doch löten? Hab mich fürs löten entschieden. Die Tastatur war mit 24 Schrauben verschraubt ;).
Einzelkabel nicht vergessen zu isolieren
Noch nen Schrumpfschlauch drüber und zack fertig: Tastatur funktioniert wieder \o/