Threema ist schon ein sehr toller Messenger, aber leider gibt es in Sachen Backup noch viel zu tun. Ein Schritt in die richtige Richtung ist der Threema Safe. Damit lassen sich grundlegende Einstellungen sichern. Unter anderem:
- Threema-ID
- Profildaten
- Kontakte
- Einstellungen
Was allerdings nicht gespeichert wird:
- Chatverläufe
- Mediendaten
Threema bietet für Threema Safe verschiedene Optionen. So kann man die Daten in der Cloud von Threema speichern, oder in einem eigenen Webdav-Verzeichnis. Da viele die Threema nutzen ausreichend paranoid sind um fremden Cloud-Speichern nicht zu verwenden und auch eine eigene Nextcloud betreiben ist die zweite Option das Mittel der Wahl.
Threema Safe in der eigenen Nextcloud
Die Nextcloud bietet alles, was Threema Safe benötigt. Eine Anleitung wie man dies einrichtet ist im Folgenden zu finden.
Serviceaccount Anlegen
Zunächst einmal sollte ein Service-Account für Threema angelegt werden. Die Threema-App benötigt Login-Daten für das Speichern des Backups. Hierfür sollte man wenn möglich nicht die Daten seinen Haupt-Accounts verwenden.
Neuen Account anlegen: Als Administrator einfach oben rechts auf den Benutzer klicken -> Benutzer -> Neuer Benutzer
Hier einfach einen Benutzernamen (z.B. „threema“ mit einem sicheren Passwort erzeugen. Passwort und Benutzername werden später benötigt.
Ordner-Sturktur anlegen
Threema verlangt eine spezielle Ordner-Sturktur auf dem Server. Legt einen beliebigen Ordner für die Backups an (möglichst ohne Leerzeichen). Innerhalb dieses Ordners MUSS ein Ordner namens „backups“ vorhanden sein. Außerdem muss eine Datei namens „config“ angelegt werden, mit folgendem bzw. ähnlichem Inhalt:
{
"maxBackupBytes": 52428800,
"retentionDays": 180
}
maxBackupBytes legt dabei die maximale Backup-Größe fest, retentionDays wie lange dieses Backup aufgehoben werden soll. Die Ordnerstruktur sollte danach etwa so aussehen:
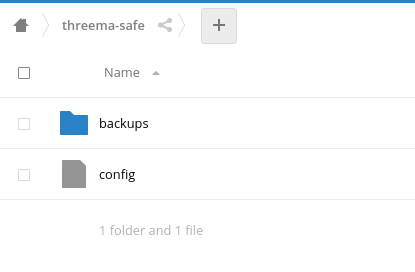
Threema Safe Konfiguration in der App einstellen
Das schlimmste ist erledigt. Nun nur noch die Einstellungen in die Threema-App übernehmen:
Burger-Menü (oben Links) -> Meine Backups -> Threema Safe
Webdav-Verzeichnis: Das Nextcloud-Verzeichnis kann mit WebDAV über folgenden Link erreicht werden:
https://cloud.website.de/remote.php/dav/files/username/subfolder
Dabei müssen natürlich die URL zur Cloud, der Benutzername und der Subfolder angepasst werden. Als Beispiel meine Konfiguration:
https://cloud.timoswebsite.de/remote.php/dav/files/threema/threema-safe
Username und Passwort wie von euch im ersten Schritt gewählt. Werden die Einstellungen gespeichert fragt Threema noch nach einem Passwort mit dem das Backup auf dem Server verschlüsselt werden soll.
Nun sollte in der Threema-App folgende Ansicht sichtbar sein:
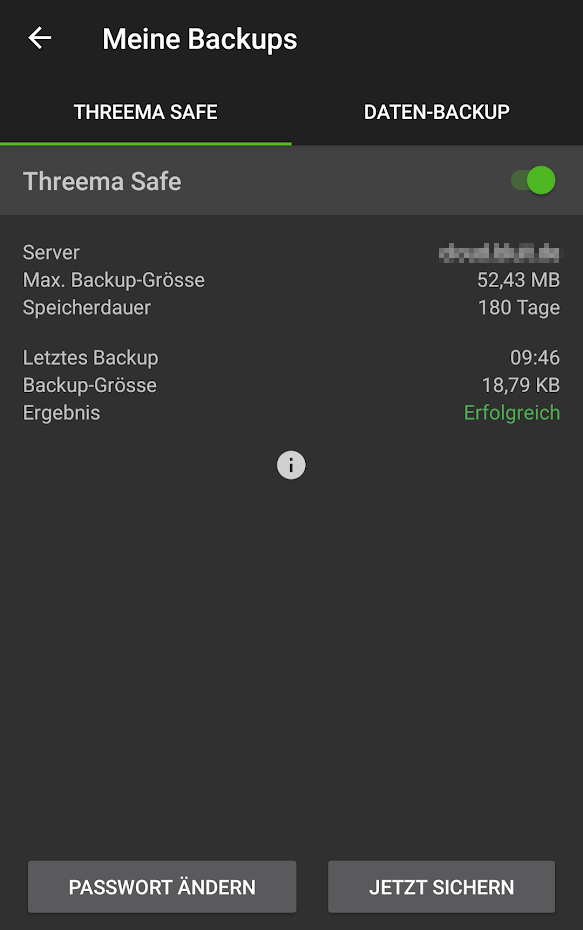
Abschließende Hinweise
Threema speichert ab jetzt selbstständig die oben genannten Daten etwa alle 24 Stunden. Aber vorsicht: Dies ist kein vollständiges Backup!
Nach wie vor werden keine Gesprächsverläufe bzw. Mediendateien gesichert. Diese müssen weiterhin über „Meine Backups -> Daten-Backup“ erstellt und vom Handy gesichert werden. Hier muss Threema definitiv noch nacharbeiten.