Zusammen mit zwei Freunden war ich 3 Wochen in Schottland um dort mit Zelt und Rucksack das Land zu bereisen. Ich bin wiedermal viel zu spät dran, um alle Eindrücke auf „Papier“ zu bringen, aber dafür gibts ein paar Anekdoten und viele Bilder vom Wandern in Schottland.
Anreise mit der Bahn
Dank der Überzeugungskraft von einer der Mitreisenden, sind wir mit dem Zug von Regensburg nach London gefahren. Zunächst zu den Fakten:
Kosten: Insgesamt hat die Bahnreise 238,80 € pro Person gekostet. Ist man realistisch und rechnet die Kosten für extra Gepäck, Bahnreise zum/vom Flughafen, etc. mit ein, kämen wir mit dem Flugzeug auf einen vergleichbaren, wenn nicht etwas günstigeren Preis.
Zeit: Das ist wohl der Knackpunkt. Die Reise hat 12 Stunden (pro Richtung) gedauert. Wenn ich hier realistisch bin, hätte diese mit dem dem Flugzeug wohl 5-6 Stunden gedauert. Im Vergleich zum fliegen, war es hier aber tatsächlich deutlich entspannter.
Thematisch passend waren wir natürlich auch beim „Harry Potter Zug“. Sind damit aber leider nicht gefahren 😉
Zusammenfassend würde ich beim nächsten Mal wahrscheinlich wieder mit dem Zug fahren. Lediglich die Reservierung der Züge und das Buchen der Tickets war ein absoluter Graus! Hier haben wir nach längerer Recherche dann loco2.com kennengelernt. Eine gute Seite mit gutem Interface. Deutlich besser als bahn.de und am Ende haben wir dann doch wieder Bahn.de-Tickets erhalten ;).
Die Menschen und das Land
Kennengelernt haben wir viele Menschen. Sowohl Engländer als auch Schotten und hatten auch mit der schottischen Polizei zu tun. Natürlich kann ich nur von den Menschen sprechen die ich kennengelernt habe, aber irgendwie hatten alle Engländer einen leichten Schlag. So wurde uns z.B. empfohlen zu behaupten wir kämen aus Frankreich, weil uns sonst alle hassen würden (war natürlich nicht der Fall).
Die Schotten wiederum kann man sehr schön mit den Bayern vergleichen. Klingen komisch, kleiden sich komisch, sind manchmal etwas grummelig, aber doch irgendwie ganz herzlich wenn man sie mal kennenlernt. Grundsätzlich aber deutlich entspannter! So trägt die Schottische Polizei nicht mal Schusswaffen mit der Begründung, die Waffengesetze seien so streng, dass die Gegenseite meisten auch nichts anderes hätte ;).
Blick auf Loch Lomond
Das Land war einfach nur unglaublich. Sowohl in Schottland (vor allem die Highlands!) als auch England (hier sind die Nationalparks sehr zu empfehlen) bietet wunderschöne Hotspots. Die schönsten Orte waren allerdings mindestens einen Tagesmarsch von der Zivilisation entfernt.
Bothys und das Hinterland
Die schönste Tour war allerdings die 3-Tagestour ins Hinterland von Schottland. Die Reise führte uns auf den zweithöchsten Berg Schottlands, zum schönsten Loch in Schottland und anschließend auf einer traumhaft schönen Tour zurück in die Zivilisation. Das besondere: Wir waren mindestens eine Tagestour von der Zivilisation entfernt. In der Nacht zuvor hat unser Zeit einen Riss bekommen und das ganze hat mich ein wenig auf den Boden der Wirklichkeit zurück geholt: Haben wir wirklich an alles gedacht? Was wenn sich jemand was bricht/etwas passiert? Wir waren aber tatsächlich gut ausgerüstet. Das Zelt kam dank Bothys nicht zum Einsatz und die fehlende Zivilisation hat allen so unendlich gut getan.
Eine winzige Bothy auf der 3-Tages-Tour
Bothys haben wir tatsächlich erst einen Tag vor der Reise kennengelernt: Ein kostenloses Hüttensystem in Schottland von dem quasi keiner weiß. Niemand darf in einer Bothy abgewiesen werden, niemand kann dir aber garantieren, dass ein Platz frei ist. Die Bothys sind völlig unterschiedliche. Es gibt sie mit mehreren Stockwerken und Kunst an der Wand oder auch nur ein Raum und statt Plumpsklo einen Spaten. So eine sieht man im Foto oben. Wir hatten das Zelt immer dabei, sollten wir mal keinen Platz bekommen, aber wir hatten immer Glück.
Wir wollen die Bilder sehen!
Jaja hier kommen sie auch schon 🙂
Bonuslevel: Verschlusssysteme
Als kleinen Bonus gibts eine kleine Auswahl von Verschlusssystemen von Türen/Toren und Zäunen in Schottland. Im Gegensatz zu England waren in Schottland quasi alle Türen und Tore unverschlossen. Und in der Form und Ausprägung der Verschlusssysteme sind die Schotten wirklich kreativ geworden. Das hat mir gefallen :).
Man kommt nach 9 Tagen Chaos Communication Camp nach Hause und ist irgendwie noch immer nicht ganz in der normalen Welt angekommen. Es war einfach unglaublich. Die Lichter, die Farben, die Menschen die man kennen lernen durfte! Und alles bedeckt mit einer leichten Staub-/Dreckschicht ob des heißen Wetters.
Irgendwie fällt es mir gerade noch etwas schwer, das erlebte in Worte zu fassen. Es gibt viel zum nachdenken und überlegen und 1000 neue Ideen. Es war wunderschön! Nun genug der gestammelten Worte und Kamera ab für ein paar Eindrücke.
tl;dr: Moskau & Rammstein waren genial! Unten sind die Bilder!
Was war denn das? Eigentlich ging es nur wegen eines Kurztrips (4 Tage) nach Moskau, angefühlt hat es sich aber wie 2 Wochen. Eine traumhaft schöne Stadt, tolle Menschen, Katzen (!) und Rammstein. Besser gehts fast nicht :).
Moskau und die Metro
Zuerst mal: Wie toll ist denn bitte diese Metro? Wir sind am Weißrussischen Bahnhof vom Flughafenexpress angekommen (extrem pünktlich) und sind direkt in die Ubahn (Metro): Ticketverkauf gestaltet sich extrem einfach. Nicht wie in Deutschland erst mal die Zone festlegen, oder den Tag oder den Aszendenten Jupiters sondern eines der folgenden Möglichkeiten wählen:
Einfache Fahrt (55 Rubel, 0,80 €)
Tagesticket (auch für mehrere Tage, 3 Tage ~240 Rubel)
Gruppenticket
Das wars. Super einfach zu bestellen, mega günstig und auch ohne Russisch einwandfrei möglich :). Und dann kommt man in diese Metro und traut seinen Augen nicht mehr! Kunst, wunderschöne Wandarbeiten und alles blitzeblank.
Es war einfach ein Traum. Alle zwei Minuten fuhr eine UBahn, das System ist leicht verstanden und man kann sich quasi nicht verlaufen. Sowas wünscht man sich in jeder Großstadt.
Katzen-Café perfekt umgesetzt
Ich möchte gar nicht so viel über Moskau erzählen, das kann man in jedem Reiseführer nachlesen. Eine Sache fand ich aber schön und das Konzept war zumindest mir neu: Sogenannte Anti-Cafés: Orte an denen man nicht für die Dienstleistung oder das Produkt bezahlt sondern für die Zeit die man dort verbringt. Perfekt umgesetzt im Anti-Café Котокафе „Котофейня“ Einem Katzencafé.
Als wäre die Vorstellung Katzen streicheln zu können nicht schon gut genug, verfolgt das Café auch noch ein geniales Konzept:
Die etwa 20-24 Katzen werden aus Tierheimen/Sheltern geholt. Es sind zumeist Katzen die dort keine neue Familie gefunden haben, weil Sie zu dünn, krank, verletzt o.Ä. sind. Im Café haben die Katzen dann ein schönes Leben, werden versorgt und von vielen Menschen gestreichelt. Wenn sie darauf keinen Bock haben, sind die Rückzugsmöglichkeiten zahlreich vorhanden. Möchte ein Besucher einer Katze ein neues Zuhause geben muss er durch eine art „Check“ (ich habe an dieser Stelle nicht genau nachgefragt) und kann dann die Katze adoptieren. So wurden schon über 100 Katzen vermittelt. Geniale Idee!
Rammstein!
Argh! Was für eine Band. Natürlich ist die Musik speziell, das muss nicht allen gefallen. Aber diese Show? Ich habe selten noch nie etwas imposanteres gesehen.
Auch hier will ich weniger über die Show reden, da lasse ich die Fotos reden. Das Drum-Herum war allerdings schon etwas anders als in Deutschland: Überall (!!) Hundertschaften (!!) von „Polizisten“. Ich verwende Anführungszeichen, da nicht sofort ersichtlich war, dass es sich um Polizei handelt, ich hatte eher den Eindruck, es würde sich um das Militär handeln.
Das hinterlies zumindest ein komisches Gefühl. Später wurden die Polizisten als Wegeleitsystem zurück zur Metro verwendet. Hier habe ich eigentlich erwartet, dass wir zumindest eine Stunde warten müssten, da gerade 50000 Menschen dort hin strömen. Pustekuchen! Alles Reibungslos, alles ohne Problem und warten.
Fotos
Und jetzt Schluss mit dem Gequatsche und endlich kommen wir zu den Fotos.
Im laufe eines Lebens sammeln sich doch so einige Konten, Ausgaben, Kredite etc an. Um nicht den Überblick zu verlieren, nutze ich für mich die Plattform Jameica mit dem Banking-Plugin Hibiscus. Dieser Artikel soll eine kleine Übersicht bieten und meine Erfahrungen zusammenfassen.
Die Jameica-Plattform ist eine freie Laufzeit-Umgebung für Java-Anwendungen, die in Form von Plugins implementiert werden können. Sie stellt ein Framework für die ganzen Plugins zur Verfügung. Hibiscus ist eine freie Homebanking-Anwendung, die vor allem für Banken interessant ist, die HBCI (vgl. API der Banken) nutzten. Durch andere Plugins können aber auch andere Banken mit erfasst werden.
Ich werde hier meine persönliche Anwendung der Software vorstellen. Man kann die Software auch für komplett andere Dinge nutzen, z.B. der Verwaltung eines Vereins. Jameica in Verbindung mit Hibiscus sieht zwar eher „altbacken“ aus, bietet aber alle Funktionen die man benötigt. Außerdem ist man nicht auf ein Betriebssystem angewiesen (vgl. Starmoney) bzw. muss für die Finanzsoftware Geld ausgeben.
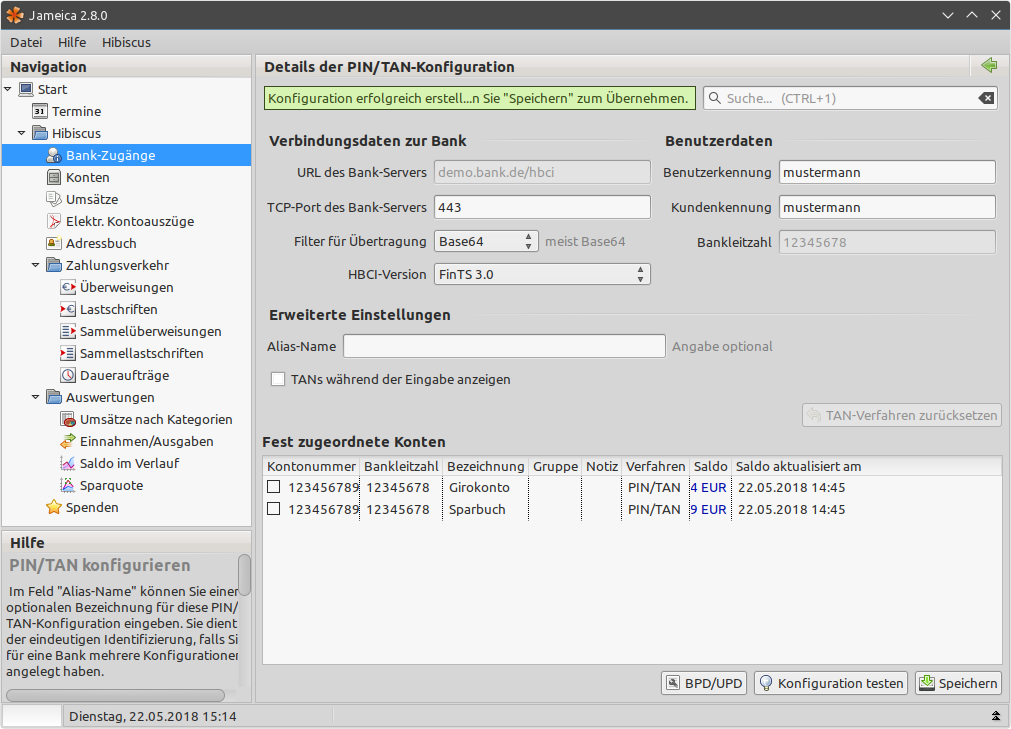
Hinweis: Bei den Screenshots habe ich sehr viel verpixelt. Meist habe ich aber einen Eintrag als Beispiel unverpixelt gelassen.
Übersicht der Transaktionen
Um eine vollständige Übersicht aller Finanztransaktionen seiner Banken zu erfassen, müssen diese erst erfasst werden. Das ist schon etwas komplexer, da man gegen die verschiedenen Bank-APIs sprechen muss. Ist es eine „normale“ Bank wie Sparkasse, ING Diba etc. ist das relativ leicht: Im Wiki des Entwicklers finden sich Anleitungen und Einstellungen für die meisten Banken: https://www.willuhn.de/wiki/doku.php?id=support:list:banken
Möchte man allerdings „Sonderbanken“ hinzufügen, gestaltet sich dies etwas schwerer und es sind weitere Plugins nötig. Bei mir sind dies z.B. die Landesbank Berlin (Kreditkarte) oder meine diversen Paypalkonten. Auch viele Bausparer nutzen nicht das HBCI verfahren.
Bisher habe ich es lediglich bei Wüstenrot nicht geschafft die Übersicht in meine Transaktions-Liste zu bringen.
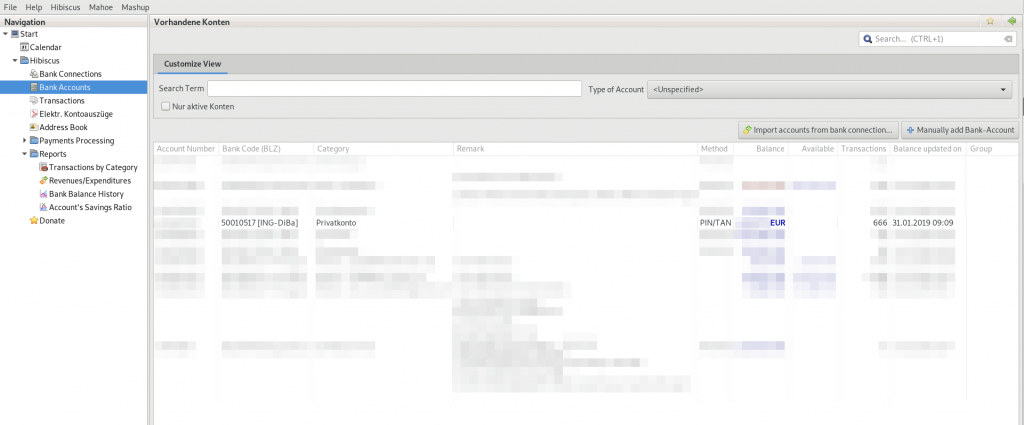
Übersicht der Konten in Hibiscus
Sind alle Konten bzw. Bank-Zugänge eingerichtet ruft Hibiscus (nur durch User-Aktion) alle Transaktionen ab. Dies kann einige Zeit dauern, da hier mit der API der jeweiligen Bank gesprochen wird. Bereits erfasste Transaktionen bleiben in einer SLQlite Datenbank gespeichert. Die Daten sind außerdem mit einem Masterpasswort verschlüsselt. Jameica selbst erstellt auch automatisch bei jedem schließen ein Backup. Um die Sicherung dieses Backups müsst ihr euch natürlich selbst kümmern.
Im Screenshot „sieht“ man die Übersicht der Konten. Hier werden die wichtigsten Informationen zusammengefasst. Ich habe auch eine Kreditkarte (zu erkennen an der roten Bilanz). Dieses Konto ist über ein Script eingebunden. Das Script erfasst dabei die aktuellen Ausgaben (Minusbilanz) und der noch zur Verfügung stehende Kredit. Die Übersicht schafft schnell einen Überblick über das gesamte zur Verfügung stehende Vermögen.
Im Übrigen können hier auch historische Daten erfasst werden. Wenn ihr z.B. eine Bank kündigt, bleiben die Transaktionen erhalten. Der Bankzugang wird dann einfach stillgelegt.
Die Transaktionen
Die Übersicht der Transaktionen bietet eine Fülle an Funktionen die im täglichen Gebrauch sehr praktisch sind.
Suche
Natürlich kann man innerhalb der Transaktionen suchen. Nun hört sich das zunächst überflüssig an, denn meisten reicht ja eine Übersicht. Wer aber am Jahresende seine Steuer machen möchte, kann hier in den Transaktionen suchen, wann etwas passiert ist und in welcher Höhe. Leider dauert die Suche bei vielen Transaktionen aufgrund der Speicherung in SQLite leider relativ lange.
Flags
Ein einfaches Flag „Confirmed“ und „Unconfirmed“ hilft bei der täglichen bzw. wöchentlichen durchschau der Daten. Ich habe einen Onlineshop und muss daher täglich die Transaktionen durchschauen. Das Flag hilft mir dabei nicht die Übersicht zu verlieren. Durch die Durchsicht fallen aber auch Posten auf, die vielleicht schon gar nicht mehr sein müssen (z.B. alte Mitgliedschaften alter Vereine, Abos, etc.) oder unberechtigte Abbuchungen durch Betrüger. Leider passiert auch dies 1-2 mal im Jahr. Wenn man es bemerkt ist das kein Problem, allerdings muss man es auch erst mal bemerken.
Kategorisierung
Jede Transaktion kann einer Kategorie zugeordnet werden. Natürlich auch vollautomatisch. Damit kann man sehr einfach „Unterkonten“ erfassen/erstellen und hat z.B. eine Übersicht über Wiederkehrende Ausgaben.
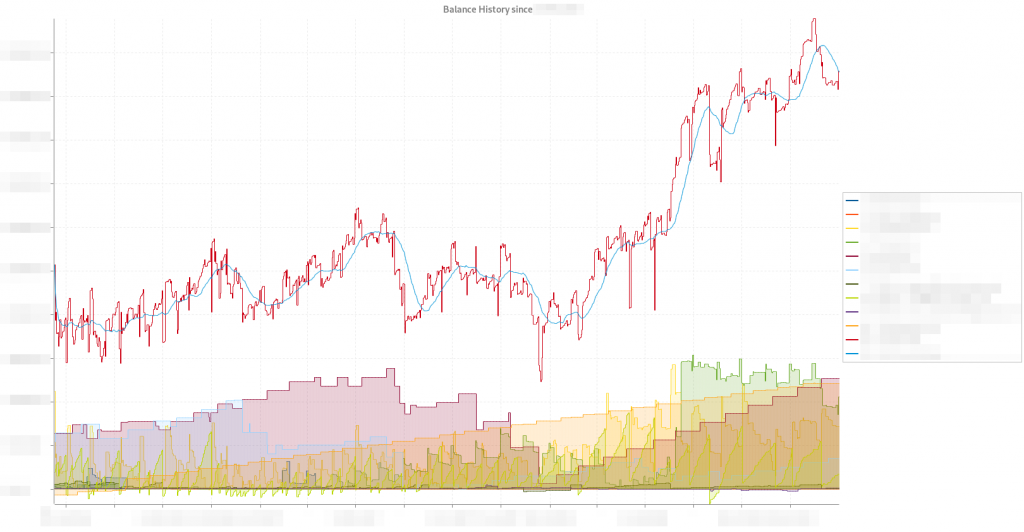
Bilanz
Ein nettes Gimik: Eine Grafische Auswertung der verschiedenen Konten. Man sieht wie die Tendenz ist, aber viel tatsächlicher Informationsgehalt ist leider nicht enthalten.
Fazit
Ich kann dieses Tool nur jedem Empfehlen. Mit der Fülle an Banken, Konten, Sparplänen, Aktien, Bausparern, Krediten, … kann man schnell die Übersicht verlieren. Jameica in Verbindung mit Hibiscus ist ein einfaches, kostenloses und umfassendes Tool um Licht ins Dunkel zu bringen. Je nachdem wie intensiv man das Tool nutzt, kann man auch weitere Erkenntnisse aus den Bilanzen ziehen.
Vorteile
Übersicht aller Transaktionen
Nahezu alle Banken
Aktive Weiterentwicklung
Freie Software
Kostenlos
Nachteile
Einige kleinere Bugs (bereits gemeldet)
Ein paar Banken gibts dann doch nicht
Ein wenig Arbeit/Gefrickel bei der Einrichtung ist nötig
Ausblick
Bei der Recherche für diesen Artikel bin ich auf synTAX gestoßen: Eine freie Finanzbuchhaltung für Selbständige und „Nichtbilanzierer“ nach SKR03/04. Die Anwendung läuft als Plugin innerhalb des Frameworks Jameica. Na das hört sich doch super an! Werde ich testen und darüber berichten :).
Zwar kann ich mich (noch) nicht mit dem Gedanken der Hausautomatisierung anfreunden, dennoch habe ich schon länger mit dem Gedanken gespielt meine Wohnung mit Sensoren auszustatten. Ich wollte die Zimmer meiner Wohnung möglichst kostengünstig mit praktischen Sensoren ausstatten.
Disclaimer: Ich arbeite hier teilweise mit Geräten die in 220V eingesteckt werden. Wenn ihr nicht wisst was ihr tut: Finger weg! Und sowieso niemals nachmachen!
Die Hardware
Was braucht man alles? Sensoren, Broker, Datenbankserver und Stromversorgung. Alles am besten aus einer Hand. Natürlich gibt es sowas, aber doch ziemlich teuer. Hier die Hardware die ich verwendet habe:
Plattform
Ideal wäre ein Grundsystem mit WLAN, Platz für Sensoren, einer stabilen Stromversorgung und idealerweise noch ein schönes Gehäuse dazu. Zum Glück gibt es so etwas Ähnliches schon:
Sonoff Socket S20
Die S20 gibt es für ~10 Euro bei Aliexpress und bieten fast alles was wir brauchen. Darin enthalten ist ein ESP der für WLAN sorgt und die Zwischensteckdose ist sogar schaltbar. Dieses Feature ignoriere ich aber zunächst, da ich derzeit noch keinen Sinn darin sehe, meine Wohnung zu automatisieren. Die S20 sind robust verbaut und wenn man diese aufschraubt, kann man man 4 Pins erreichen, an die Sensoren angeschlossen werden können: Fast perfekt
Leider ist das Gehäuse vollständig geschlossen, weswegen ich die 4 Pins für die Sensoren nach außen gelegt habe.
Sensoren
Bei der Wahl der Sensoren habe ich mich aufgrund der limitierten Pin-Anzahl für I²C Sensoren entschieden. Diese können parallel zueinander an die 4 Pins gehängt werden. Mögliche Sensoren (eine Auswahl):
BMP280
Luftdruck
Temperatur
Luftfeuchtigkeit
~2-3 Euro
BH1750
Helligkeit
~1-2 Euro
CCS811
Luftqualität
~10 Euro
BME680
Luftdruck
Temperatur
Luftfeuchtigkeit
Luftqualität
~15 Euro
Ich hab mich zunächst mal nur für BMP280 (sehr günstig und sehr praktisch) und den BH1750 (kostet fast nix, ich weiß noch nicht was ich mit den Werten anfange) entschieden.
Die Luftqualitätssensoren habe ich bestellt und ein Test steht noch aus. Allerdings bin ich noch nicht ganz überzeugt. Ich hätte gerne einen C0x Sensor aber sowas ist einfach super teuer.
Hardware zusammenbauen
Im Grunde muss für die Vorbereitung der Hardware einige Kabel angelötet werden, die Sensoren aufgesteckt werden und eine neue Firmware konfiguriert werden.
S20 vorbereiten und neue Firmware flashen
Der Sonoff S20 kann über das Lösen von drei Schrauben geöffnet werden. Anschließend kann man auf der Platine vier Anschlussmöglichkeiten. Da es absolut nicht zu empfehlen ist, bei geöffnetem Gehäuse die S20 mit Strom zu versorgen. Die Anschlüsse können über vier Kabel und einem kleinen Loch nach draußen geführt werden.
Die Platine eines Sonoff S20 mit aufgelöteten Kabeln
Verbesserungsidee für die Profis: Vierpolige Klinkenstecker bzw. -buchsen eigenen sich hervorragend um die Anschlüsse sauber nach draußen zu führen.
Das Pinout ist in folgendem Bild zu erkennen:
Pinout Sonoff S20
Firmware konfigurieren
Als Firmware verwende ich ESPEasy (Github, Hauptseite). Dazu benötigt man zunächst die Software aus dem neusten Release von Github: https://github.com/letscontrolit/ESPEasy/releases und den dazu passenden Flasher für ESPs. Da die Anleitung etwas ausführlicher ist und ich dieses noch an einem Beispiel nachvollziehen muss, würde ich zunächst hierauf verzichten und dies noch nachreichen. Wenn ihr es trotzdem vermisst, einfach einen Kommentar schreiben.
Sensorpaket löten
Die angesprochenen I2C Sensoren können parallel angebracht werden und benötigen neben der Stromversorgung nur zwei Leitungen. Zu beachten ist dabei nur:
Sonoff S20
Sensor
GND
GND
VCC
VIN/VCC
RX
SDA
TX
SCL
Zwei Sensoren gestapelt
Sonoff S20 konfigurieren
Die neue Firmware stellt ein Webinterface zur Verfügung. Die IP-Adresse wird dabei beim Flashen angezeigt. Solltet ihr verpasst haben, die IP-Adresse zu notieren, könnt ihr in eurem Router nochmal nachsehen oder die IP-Adresse per nmap herausfinden.
Auf die Beschreibung der üblichen Konfigurationen wie WIFI, NTP und Co verzichte ich an dieser Stelle. Hier kann man sich gut durchklicken und die Infos sollten klar sein.
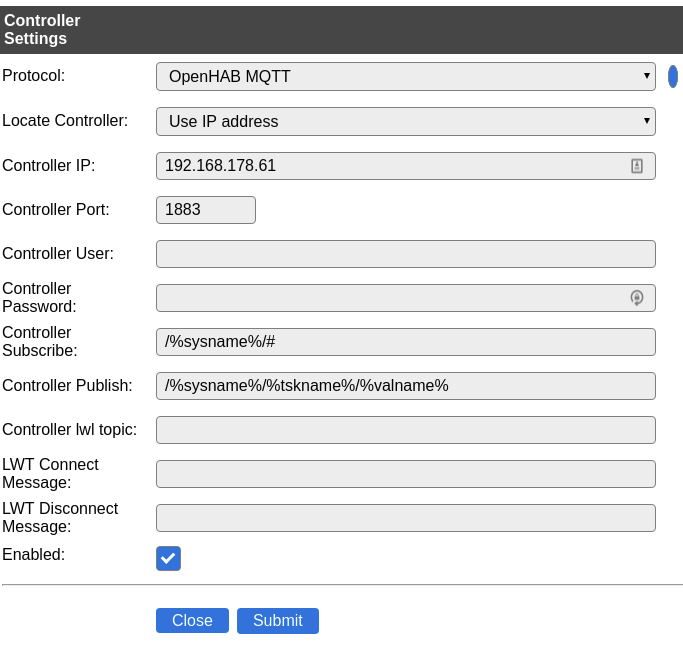
Controller konfigurieren
Für den Controller verwenden wir ein Raspi. Wie dieser konfiguriert wird, ist weiter unten zu sehen. Leider beißt sich hier die Katze in den Schwanz, denn für die Konfiguration benötigt man die IP-Adresse des Controllers. Bitte zunächst also den Raspi fertig einrichten und hier wieder weitermachen. Der Controller ist dazu da, die Daten, die am ESP Easy erfasst werden, weiterzuverarbeiten und zu speichern. Eine Beispielkonfiguration für den Raspi sieht wie folgt aus:
Controller-Konfigratuion für den Raspi
I2C Sensoren aktivieren
Um Pins für die Sensoren frei zu kriegen, muss zunächst der serielle Port abgeschaltet werden. Unter Tools -> Advanced -> Enable Serial Port deaktivieren. Anschließend den Controller neustarten. Danach unter Hardware -> I2C Interface die korrekten Pins einstellen:
Pinbelegung für die Sonoff S20
Wenn die Sensoren angeschlossen sind können diese über Tools -> I2C Scan getestet werden. Die Ausgabe sollte dabei wie folgt aussehen:
I2C Scan bei ESP Easy
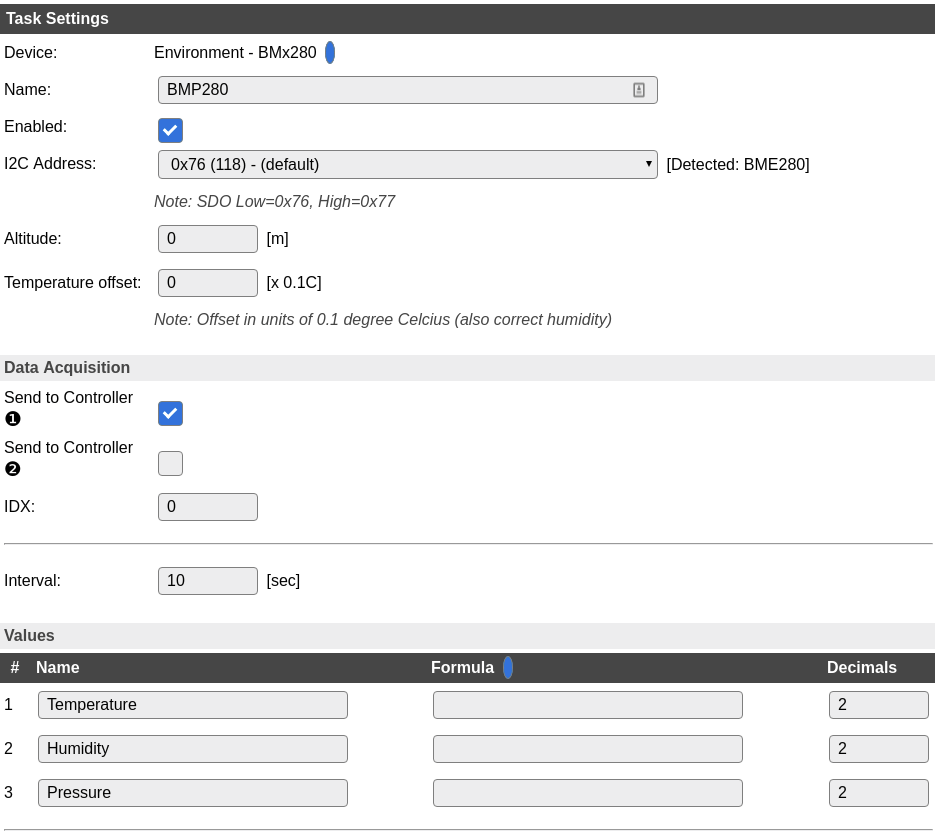
Im obigen Beispiel werden zwei Sensoren erkannt und gleich die vermuteten Sensoren angezeigt. In diesem Fall: BH1750 und BMP280. Die Sensoren können nun über Devices konfiguriert werden. Hier ein Beispiel für den BMP280. Zu beachten ist, dass „Send to Controller“ nicht aktiv ist, solange kein Controller konfiguriert ist. Ein Controller muss zunächst installiert werden.
Als Server fungiert ein einfacher Raspberry Pi 3 (35 €). Hier funktioniert aber alles auf dem man folgende Tools installieren kann:
InfluxDB
Grafana (optional)
Telegraf
Mosquitto
Ein allgemeiner Hinweis: Ich gehe in diesem Beitrag aus gründen der Komplexität nicht auf die Sicherheit eurere Systeme ein. Bitte informiert euch selbst, wie ihr
Rasbian installieren
Als Betriebssystem für den Rapsi verwende ich Rasbian. Dazu gibt es offizielle Anleitungen, wie dieses installiert werden kann. In dieser Anleitung verzichte ich darauf.
Mosquitto installieren
Mosquitto ist ein einfacher MQTT message broker. Die Installation und das starten ist dabei relativ einfach:
Mosquitto kann über das File /etc/mosquitto/mosquitto.conf konfiguriert werden. Wenn man keine Authentifizierung möchte, reicht die standard-config aus.
InfluxDB installieren
Als Datenbank-Backend verwenden wir InfluxDB. influx ist eine Zeitreihendatenbank und eignet sich besonders gut für die Art der erfassten Daten. Dazu zunächst die Datei /etc/apt/sources.list.d/influxdb.list mit folgendem Inhalt erstellen:
deb https://repos.influxdata.com/debian stretch stable
Achtung: Hier wird eine Paketquelle aus einer potentiell nicht vertrauenswürdigen Quelle verwendet. Dies ist immer mit Vorsicht zu genießen. Da dies aber die Paketquelle von Influx selbst ist, ist diese relativ vertrauenswürdig.
Nun werden wir root, installieren den RSA-Key von influx und installieren die Datenbank:
sudo su curl -sL https://repos.influxdata.com/influxdb.key | apt-key add -
apt update apt install influxdb
Telegraf installieren und konfigurieren
Um die mqtt-Daten zu erfassen, kann Telegraf verwendet werden. Nebenbei erhält man dann auch noch Daten der Auslastung des Raspi. Das Paket telegraf kommt aus den selben Quellen wie die influx-Datenbank.
apt install telegraf
Nach der Installation muss die Config-Datei unter /etc/telegraf/telegraf.conf angepasst werden. Die Meisten Punkte müssen lediglich auskommentiert werden. Wenn keine weiteren Änderungen nötig sind, kann der unten stehende Config-Teil auch einfach ans Ende der Datei kopiert werden.
# Read metrics from MQTT topic(s)
[[inputs.mqtt_consumer]]
## MQTT broker URLs to be used. The format should be scheme://host:port,
## schema can be tcp, ssl, or ws.
servers = ["tcp://localhost:1883"]
## Topics to subscribe to
topics = ["#",]
## Pin mqtt_consumer to specific data format
data_format = "value"
data_type = "float" ist
Anschließend müssen noch beide Services enabled und gestartet werden.
Grundsätzlich reicht dieses Setup schon aus. Auch können ab jetzt schon die Daten in der InfluxDB gefunden werden. Allerdings wollen wir die Daten auch visuell besser aufbereiten.
Grafana Installieren
Grafana eignet sich hervorragend für die Darstellung der von uns erfassten Daten. Leider ist die Version des grafana im rapsi-repo sehr alt, daher nehmen wir auch hier eine andere Version. Weitere Informationen zur Installation der Paketquellen zu grafana sind hier zu finden: http://docs.grafana.org/installation/debian/ Erstellt dazu /etc/apt/sources.list.d/grafana.list mit folgendem Inhalt:
deb https://packages.grafana.com/oss/deb stable main
Achtung: Hier wird eine Paketquelle aus einer potentiell nicht vertrauenswürdigen Quelle verwendet. Dies ist immer mit Vorsicht zu genießen. Dies ist allerdings der von Grafana selbst gewählte Weg. Nun muss noch der GPG-Key für das Grafana-Paket installiert werden:
Ab jetzt kann man unter der IP-Adresse des Raspis und dem Port :3000 Grafana erreichen:
http://192.168.123.123:3000
Für die weitere Konfiguration einfach dem Webinterface folgen und z.B. einen Benutzer einrichten bzw. Passwörter ändern. Der Standard-Benutzer ist admin mit dem Passwort admin.
Beispiel für Darstellung erfasster Daten
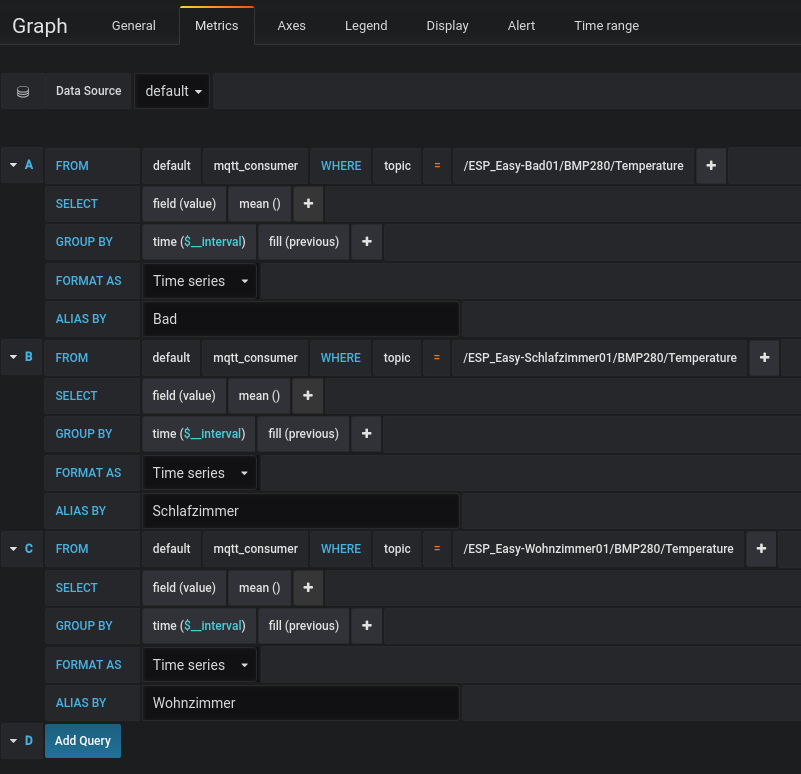
Ab hier sind euch alle Freiheiten gegeben, die erfassten Daten grafisch aufzubereiten. Als Beispiel die Erfassung der Raumtemperatur mit drei Sensoren. Dazu einfach ein „Panel“ hinzufügen und folgende Daten erfassen:
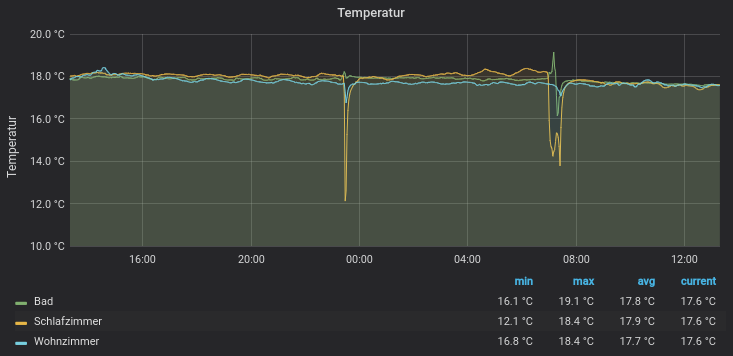
Beispiel für die grafische Aufbereitung der erfassten Daten mit Grafana
Anschließend können noch die Achsen und die Legende bearbeitet werden. Hier empfiehlt es sich die verschiedenen Einstellmöglichkeiten einfach durchzubprobieren. Man hat hier sehr viele Einstellmöglichkeiten. Anschließend sollten die Daten aufbereitet werden und als Grafik dargestellt werden:
Gimiks
Da wir nun Telegraf für die Datenerfassung nutzen, können wir auch die Daten des Rapsi auswerten. Telegraf erfasst alle Daten des Raspi automatisch. Also Load, Temperatur, CPU Auslastung etc. Natürlich ist das nicht nötig, aber wenn wir die Daten schon erfassen, können wir diese doch auch gleich mit Grafana auswerten. Eien tolle Funktion in Grafana: Man kann sich fertige Dashboards hinzufügen. Unter https://grafana.com/dashboards findet man verschiedene fertige Dahsboards mit einer dazugehörigen ID. Beispiele für Telegraf sind z.B. das Dashboard mit der ID 61 oder 928. Dazu einfach seitlich auf das „+“ -> Import Dashboard und anschließend die gewünschte ID eingeben. Im folgenden Dialog muss noch die Datenquelle (InfluxDB) angepasst werden auf telegraf.
Beispiel-Dashboard für Telegraf (928)
Updates
[04.02.2019] Update der Paketquellen und Gimiks
Grafana hat nun endlich selbst eine Paketquelle für das aktuelle Grafana. Dies wurde in der Anleitung ergänzt.
Es gibt jetzt auch die Anleitung wie ich die Prozessdaten des Raspi erfassen kann.
[11.02.2019] Mosquitto ergänzt
Ich habe doch tatsächlich den Teil über Mosquitto vergessen. ist jetzt ergänzt.
Threema ist schon ein sehr toller Messenger, aber leider gibt es in Sachen Backup noch viel zu tun. Ein Schritt in die richtige Richtung ist der Threema Safe. Damit lassen sich grundlegende Einstellungen sichern. Unter anderem:
Threema-ID
Profildaten
Kontakte
Einstellungen
Was allerdings nicht gespeichert wird:
Chatverläufe
Mediendaten
Threema bietet für Threema Safe verschiedene Optionen. So kann man die Daten in der Cloud von Threema speichern, oder in einem eigenen Webdav-Verzeichnis. Da viele die Threema nutzen ausreichend paranoid sind um fremden Cloud-Speichern nicht zu verwenden und auch eine eigene Nextcloud betreiben ist die zweite Option das Mittel der Wahl.
Threema Safe in der eigenen Nextcloud
Die Nextcloud bietet alles, was Threema Safe benötigt. Eine Anleitung wie man dies einrichtet ist im Folgenden zu finden.
Serviceaccount Anlegen
Zunächst einmal sollte ein Service-Account für Threema angelegt werden. Die Threema-App benötigt Login-Daten für das Speichern des Backups. Hierfür sollte man wenn möglich nicht die Daten seinen Haupt-Accounts verwenden.
Neuen Account anlegen: Als Administrator einfach oben rechts auf den Benutzer klicken -> Benutzer -> Neuer Benutzer
Hier einfach einen Benutzernamen (z.B. „threema“ mit einem sicheren Passwort erzeugen. Passwort und Benutzername werden später benötigt.
Ordner-Sturktur anlegen
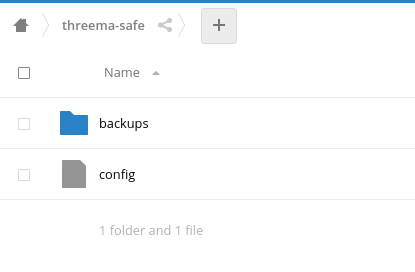
Threema verlangt eine spezielle Ordner-Sturktur auf dem Server. Legt einen beliebigen Ordner für die Backups an (möglichst ohne Leerzeichen). Innerhalb dieses Ordners MUSS ein Ordner namens „backups“ vorhanden sein. Außerdem muss eine Datei namens „config“ angelegt werden, mit folgendem bzw. ähnlichem Inhalt:
maxBackupBytes legt dabei die maximale Backup-Größe fest, retentionDays wie lange dieses Backup aufgehoben werden soll. Die Ordnerstruktur sollte danach etwa so aussehen:
Threema Safe Ordnerstruktur in der Nextcloud (Web-Ansicht)
Threema Safe Konfiguration in der App einstellen
Das schlimmste ist erledigt. Nun nur noch die Einstellungen in die Threema-App übernehmen:
Username und Passwort wie von euch im ersten Schritt gewählt. Werden die Einstellungen gespeichert fragt Threema noch nach einem Passwort mit dem das Backup auf dem Server verschlüsselt werden soll.
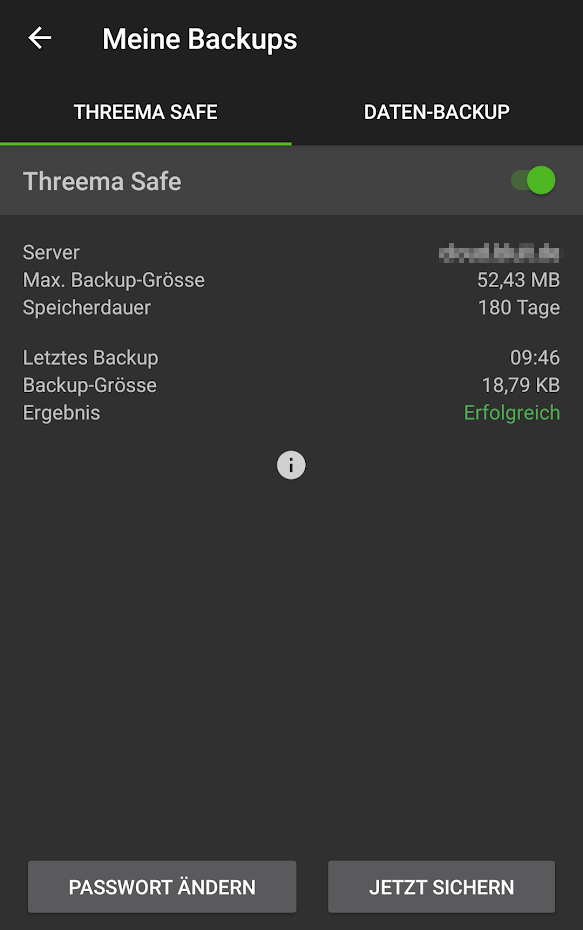
Nun sollte in der Threema-App folgende Ansicht sichtbar sein:
Threema Safe Einstellungen auf dem Handy mit der Nextcloud
Abschließende Hinweise
Threema speichert ab jetzt selbstständig die oben genannten Daten etwa alle 24 Stunden. Aber vorsicht: Dies ist kein vollständiges Backup!
Nach wie vor werden keine Gesprächsverläufe bzw. Mediendateien gesichert. Diese müssen weiterhin über „Meine Backups -> Daten-Backup“ erstellt und vom Handy gesichert werden. Hier muss Threema definitiv noch nacharbeiten.
Heute gibt es mal wieder ein bisschen Spezielleres. Ich verkaufe ja Bier im Internet und benötige für meine Halle ein Regalsystem, in welchem ich viele Bierkisten passen. Fertige Regalsysteme im Netz fangen bei 300 Euro an. Das geht selbst besser.
Bauteile und Kosten
Da ich in der Halle viel Platz nach oben habe, wird das Regalsystem sehr hoch:
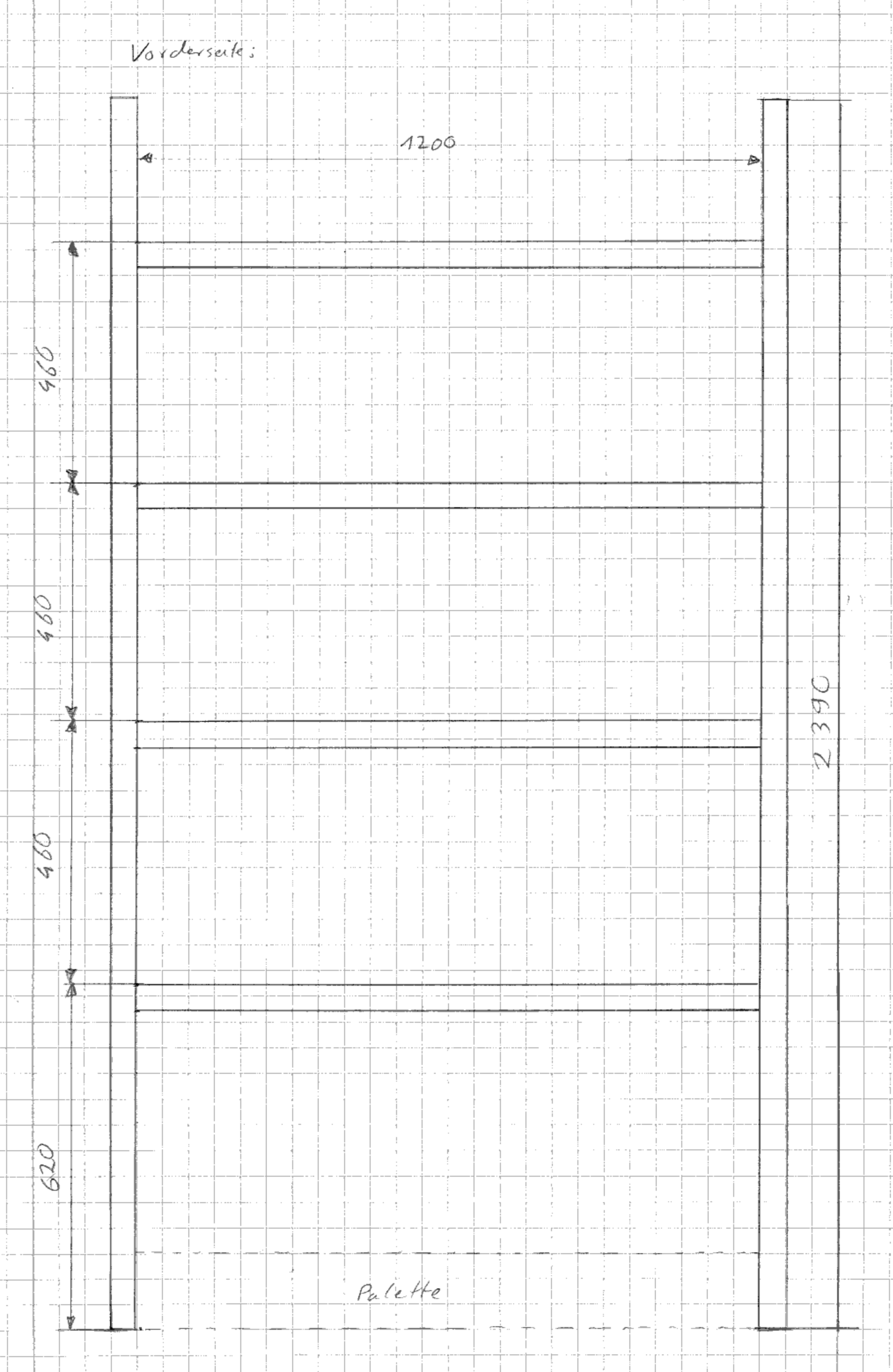
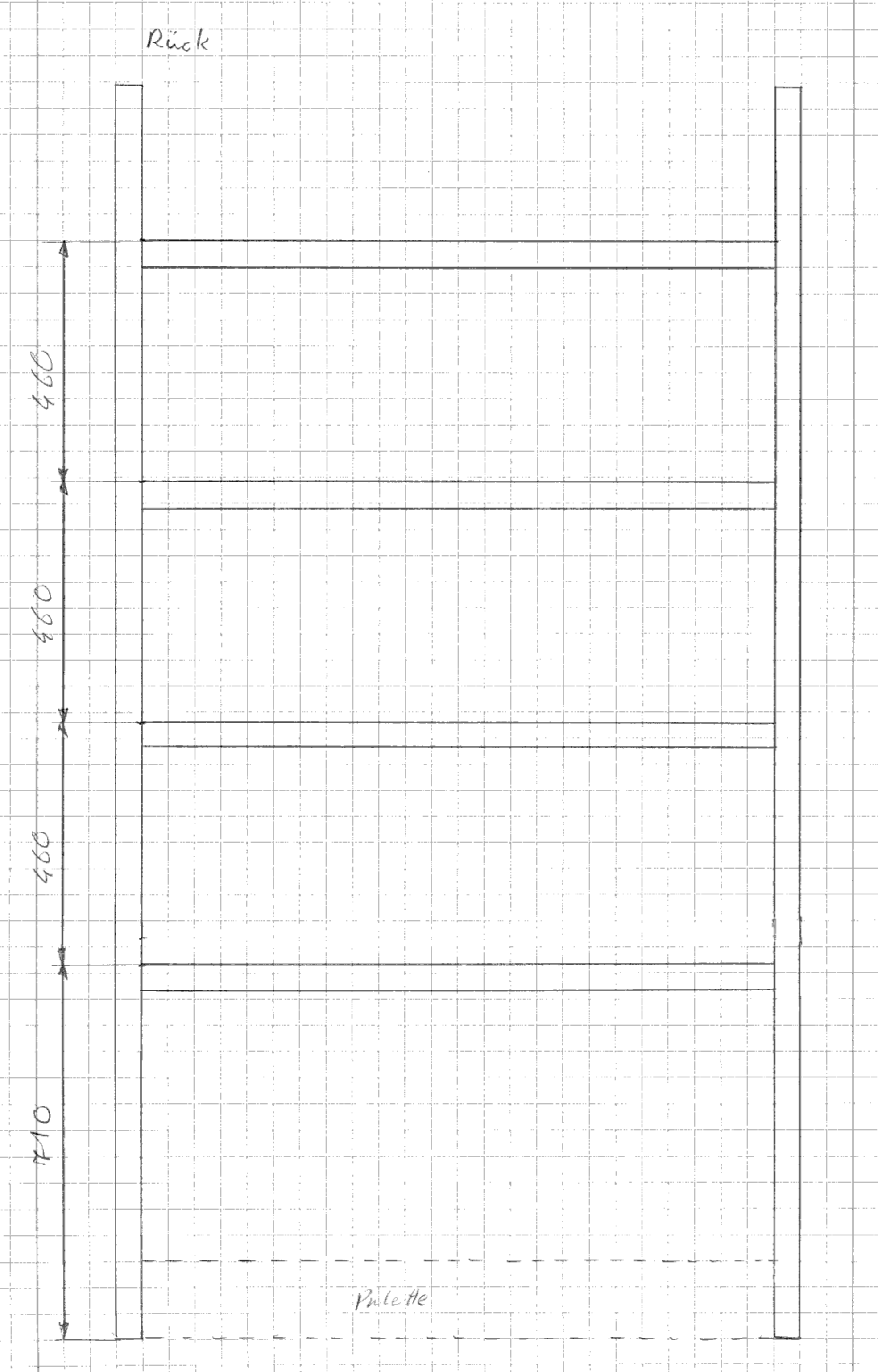
Höhe: ~2400 mm
Breite: ~1300 mm
Tiefe: ~400 mm
Die Breite ist so gewählt, dass genau vier Euro-Bierkisten nebeneinander passen und das Ganze auf eine Palette passt.
Insgesamt werden acht 30×50 mm Latten mit einer Länge von 3000 mm benötigt. Im Baumarkt um die Ecke gibt es das sägerau für 1,50 pro Latte. Insgesamt also 12 Euro.
Konstruktion und Zusammenbau
Ich habe zunächst die Latten auf Länge gesägt. Insgesamt werden benötigt:
4x 2390 mm
8x 1200 mm
8x 340 mm
Es ist nicht unbedingt nötig aber die sägerauen Latten sind nicht sonderlich schön. Daher noch eine Runde über den Hobel mit allem.
Wenn alle Latten vorbereitet sind kann der Zusammenbau beginnen.
Die Latten der Voderseite sind 90 mm niedriger als auf der Rückseite. So bekommen die Kästen eine leichte Schräge und die Flaschen können besser entnommen werden. Das Ganze ist so konstruiert, dass auf die Palette nochmal eine Ebene an Kisten normal hingestellt werden kann. Pro Latte passen 4 Kisten, also Pro Regal 24 Kisten. Die Latten müssen viel aushalten, daher am besten mehrere (mindesten 2) Schrauben pro Latte verwenden.
Nachdem Vorder- und Rückseite montiert sind, können beide über Latten auf der Seite (340 mm) verbunden werden. Hier sind die Abstände nicht wichtig. Am besten über die gesamte höhe gleich verteilen.
Montage auf der Palette
Die Montage auf der Palette war relativ einfach. Ich habe diese lediglich mit jeweils 8 langen Schrauben im Holz der Europalette verankert. Bei der Montage des zweiten Regals ist aufgefallen, dass man hier etwas tiefer (etwa 10 cm) ansetzen sollte, da man sonst mit den überstehenden Ecken der Rückseite der Kisten an die des anderen Regals stößt. Dadurch verliert man die unterste Reihe direkt auf der Palette.
Fazit
Mit einfachsten Mitteln und etwa 20 Euro Geldeinsatz bekommt man ein Regal mit extra viel Platz und Stauraum. Das Regal steht jetzt schon mehrere Wochen voll beladen und hält nach wie vor einwandfrei.
die Entwicklung schreitet manchmal mit weiten Schritten voran und man muss immer am Ball bleiben um auf dem neusten Stand zu sein. Und so hab ich mir gitea mal etwas genauer angesehen.
Was ist gitea, gogs, gitlab?
gitea ist ein fork von gogs einem wirklich sehr coolem und Ressourcen sparenden github.com Klon. Mit beiden Systemen kann man sich quasi sein ganz persönliches github aufbauen und zwar auf seinen eigenen Servern.
Im übrigen lasse ich gitlab für mich mal vollkommen außen vor, weil es mir kalt über den Rücken läuft, wenn ich an Ruby on Rails Anwendungen denke und zudem gogs/gitea deutlich (!) Ressourcen sparender ist.
Ich selbst betreibe zwei Instanzen von gogs (privat und in der Forschungsgruppe) und möchte in diesem Artikel auch die Erfahrungen mit der Migration teilen.
Warum plötzlich gitea und nicht weiter mit gogs?
Wie bereits gesagt ist gitea ein Klon vom quelloffenen gogs. Die Hauptentwicklung bei gogs hing mehr oder weniger an einer Person und die Entwicklung stagnierte in letzter Zeit enorm. In gitea sind mittlerweile einige Feature eingearbeitet, welche so nicht bei gogs vorkommen. Einige Beispiele:
GPG verification
2-Faktor-Authentifizierung
OpenID
Vor Allem hat mich die 2-Faktor-Authentifizierung überzeugt. Auch glaube ich, dass die Entwicklung durch mehr Personen einfach mehr leisten und schneller Updates bringt.
Gitea ist ja schön und gut, aber wie migriere ich von gogs?
Ich habe nun insgesamt 2 Instanzen von gitea aufgesetzt:
Neuinstallation unter Debian 9 (Stretch)
Migration von gogs 0.11.19.* unter Arch
Neuinstallation von gitea unter Debian 9 (Stretch)
Die einfachste Variante ist wohl die Neuinstallation. Alle der folgenden Befehle werden als sudo ausgeführt. Zunächst sollte ein User angelegt werden:
adduser --system git
Stellt sicher, dass git Installiert ist:
apt-get install git
Anschließend Ordner erstellen, gitea herunterladen und rechte anpassen:
Nun kann man gitea bereits mit folgendem Befehl starten:
./gitea web
Dieser Befehl legt auch schonmal eine leere config-datei unter /opt/gitea/custom/conf/ an.
Wir möchten gitea aber nicht ständig manuell starten und legen stattdessen ein .service-file für systemd an. Dazu im die Datei /etc/systemd/system/gitea.service mit folgendem Inhalt anlegen:
[Unit]
Description=Gitea
After=syslog.target
After=network.target
After=mariadb.service mysqld.service postgresql.service memcached.service redis.service
[Service]
# Modify these two values and uncomment them if you have
# repos with lots of files and get an HTTP error 500 because
# of that
###
#LimitMEMLOCK=infinity
#LimitNOFILE=65535
Type=simple
User=git
Group=git
WorkingDirectory=/opt/gitea
ExecStart=/opt/gitea/gitea web
Restart=always
[Install]
WantedBy=multi-user.target
Mit folgenden Befehlen kann nun gitea gestartet, gestopt und enabled werden (Achtung: Vorher den Befehl „systemctl daemon-reload“ ausführen):
Es wird ein einfacher proxy_pass angelegt. Gitea sollte damit im Internet erreichbar sein. Nun noch wie üblich eine Datenbank anlegen (ich gehe davon aus, das schafft ihr) und man kann auch schon los legen.
Migration unter Arch
Zunächst einmal muss gitea installiert werden. Ich empfehle dabei das gitea aus dem user repository (mehr Infos: https://wiki.archlinux.org/index.php/Gitea) zu nehmen. Ich selbst habe mich dafür entschieden, die installation analog zu der unter Debian zu machen, da ich hier gerne das Upgrade selbst durchführen will.
Leider funktioniert die einfache Migration wie hier beschrieben nicht mehr: https://docs.gitea.io/en-us/upgrade-from-gogs/ Dazu wäre Version 0.9 nötig. Ich habe leider auch keine elegante Variante gefunden. Ich habe zwar die aufgezeigte Migration versucht, aber die Datenbank ist einfach nicht mehr konsistent. Einzige Migrationsmöglichkeit ist es, die Repos einzeln zu migrieren.
Normalerweise halte ich mich ja vor Dingen fern, die „Volks-“ im Namen haben, aber die Volksverschlüsselung des Fraunhofer SIT klingt einfach zu verlockend.
TL:DR; Bei der Volksverschlüsselung erhält man nach Authentifizierung ein für 2 Jahre gültiges S/MIME Zertifikat. Leider ist das Zertifikat selbst signiert, aber das Fraunhofer Institut arbeitet wohl schon an einer Aufnahme in die trusted stores.
Was ist S/MIME?
Secure / Multipurpose Internet Mail Extensions (S/MIME) ist ein toller weg seine Emails zu signieren und zu verschlüsseln. Es ist vergleichbar mit GnuPG ist aber deutlich besser in alle Email-Clients integriert und man benötigt keine Plugins oder Erweiterungen. Mehr dazu hier: http://t3n.de/news/mails-verschlusseln-eigentlich-482381/
Wie bekomme ich das Zertifikat?
Da für das Zertifikat der vollständige Name überprüft werden muss, funktionieren derzeit leider nur folgende Verifikationsmethoden:
Personalausweis: Man nutzt die tollen Funktionen des Personalausweises und hat ein Lesegerät dafür.
Telekom: Man ist Festnetzkunde der Telekom und kann über die Rechnung seinen Namen verifizieren
Registrierungscode: Man findet jemanden vom Fraunhofer auf einer Veranstaltung und lässt sich vom Mitarbeiter verifizieren.
Die letzte Methdoe habe ich gewählt und beschreibe im Folgenden wie man sich das Zertifikat holt.
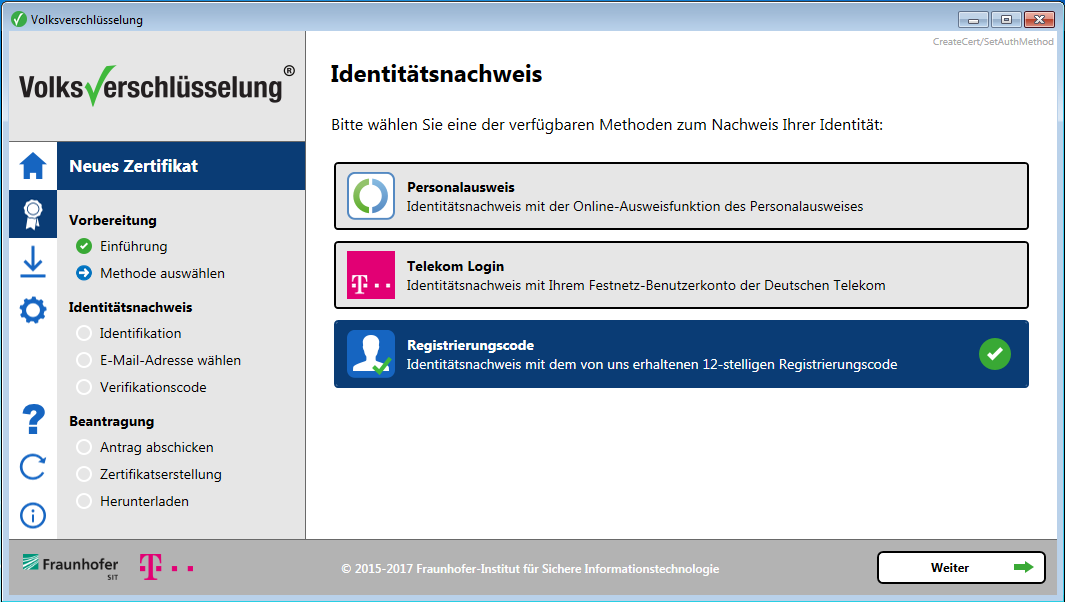
Leider gibt es die Antrags-Software derzeit nur für Windows. Daher empfehle ich einfach kurz eine Windows VM anzulegen und mit der Software ein Zertifikat beantrage. Das Tool einfach herunterladen, installieren und folgende Identitäsnachweis wählen:
Anschließend Email-Adresse und Antrags-Code auf der Karte eingeben. Nach der Überprüfung wird noch ein Bestätigungscode auf die angegebene Email-Adresse geschickt und schon ist der Antrag fertig.
Vergesst nicht euren Sperrcode sicher aufzuheben. Dieser wird benötigt, wenn das Zertifikat vor dem Ablaufdatum zurückgezogen werden muss.
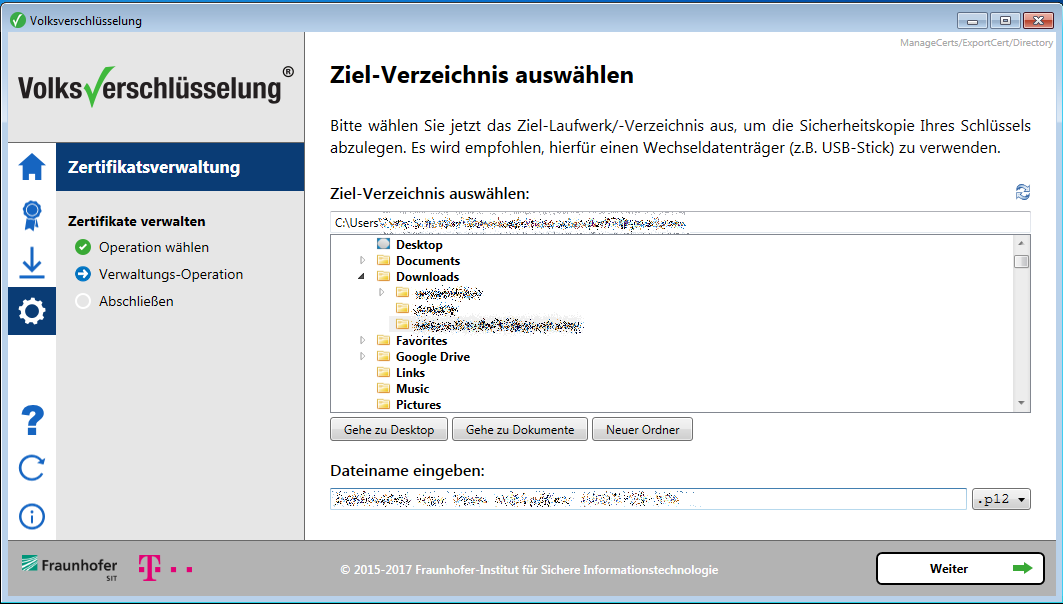
Zertifikat exportieren
Zum exportieren des Zertifikates, muss links im Menü das Zahnrad ausgewählt werden und anschließend „Zertifikat exportieren“. Achtet darauf, dass ihr ein .p12 Zertifkat exportiert. Dieses kann in der Regel für alle Systeme verwendet werden.
Zertifikat in Thunderbird einbinden
Die Einbindung in Thunderbird ist dann eigentlich ein Kinderspiel. Man geht zu seinen Email-Konten (unter Linux: Bearbeiten -> Konten Einstellungen -> S/MIME-Sicherheit.
Anschließend wählt man für die Digitale Unterschrift und Verschlüsselung das richtige .p12 Zertifikat aus (gibt dann noch ein eventuell vergebenes Passwort ein) und schon wars das.
Es muss dann außerdem unter Bearbeiten -> Einstellungen -> Erweitert -> Zertifikate Verwalten das Zertifikat vom „Fraunhofer SIT“ suchen und bei allen Zertifikaten das „Vertrauen bearbeiten“ und alle drei Häckchen setzen.
Um zu testen, ob alles funktioniert hat, sendet das System automatisch eine verschlüsselte Email. Wenn alles richtig eingerichtet ist, solltet ihr die Nachricht ohne Probleme entschlüsseln können.
Herzlich Willkommen auf meinem kleinen privaten Blog!
Dieser Blog ist vor langer Zeit entstanden um die daheim gebliebenen mit Fotos und Geschichten über meinen Neuseelandaufenthalt zu informieren. Mittlerweile sind aber auch andere Geschichten dazu gekommen. Neben einigen Hilfestellungen für Computerprobleme (vor allem Linux) berichte ich auch von meinem Onlineshop shop.blinkyparts.com. Schaut euch einfach ein bisschen auf meiner Seite um und hinterlasst einen Kommentar.